top of page

BASES DE DATOS
ASIR

🌐 ENLACES EXTERNOS
📝 APUNTES
📚 T1 Sistemas de almacenamiento
🟨 * Comandos Básicos Oracle SQL
🔶 T2 Diseño Conceptual y Lógico
🧱 T3, T4 y T5 SQL Developer
☑️ T6 Optimizar Consultas (Índices)
📙 T7 Construcción Guiones (PL/SQL)
🔒 T8 Gestión de Seguridad (EXP-IMP)
💼 T9 BBDD Distribuidas
LEYENDA DE COLORES
▉ BLANCO Archivos / Encabezados / Palabras destacadas / Output resultante de un comando
▉ [PARÉNTESIS] [Parámetros a introducir en una línea de comandos] / [teclas]
▉ GRIS Introducciones / Aclaraciones / Texto explicativo / Datos
▉ VERDE Código / Activo
▉ VERDE PÁLIDO Atributos / Columnas
▉ AZUL Secciones / Rutas / Carpetas
▉ AZUL CLARO URLs / Internet / Tipos de dato
▉ ROSA Resaltado
▉ ROSA OSCURO Output
▉ ROJO Atención / Oracle / Error / Inactivo
▉ NARANJA Usuarios / Contraseñas / Entidades / Tablas / lenguaje PL/SQL
▉ AMARILLO SQL / Base de Datos / Relaciones / Índices / Variables
T1_BBDD
📚 BASES DE DATOS TEMA 1 - SISTEMAS DE ALMACENAMIENTO
📁 Archivos según su organización:
- Acceso secuencial (cintas magnéticas)
- Acceso directo (discos duros)
📁 Archivos según su contenido:
- Texto, planos o ASCII (html, java, sql..)
- Binario (audio imagen vídeo)
📚 Bases de datos - Definición:
Podemos definir una base de datos como un conjunto de información relacionada que se encuentra agrupada o estructurada. Unos datos almacenados que pertenecen a un mismo CONTEXTO.
Una base de datos se compone de:
- TABLAS
- Las tablas se componen de ATRIBUTOS (columnas)
- REGISTRO (conjuntos de datos del mismo concepto)
- El DATO (información concreta sobre un atributo)
* Las bases de datos pueden tener usos de distinta naturaleza y con distinto objetivo.
Bases de datos según los cambios que puedan sufrir:
- Estáticas o históricas (sólo lectura)
- Dinámicas (editables)
Bases de datos según el número de sitios donde esté ubicada aquella:
- Centralizado (servidor central único)
- Distribuido (información troceada en distintos servidores)
Características de una base de datos:
- Integridad y coherencia (los datos tienen condicionantes o requisitos)
- No redundancia e inconsistencia (no repetir datos en diferentes tablas)
- Restricciones de seguridad (medios técnicos para que solo accedan usuarios autorizados)
- Protección ante fallos (mecanismos que ayudan a corregir dichos fallos)
- Acceso concurrente (que más de un usuario puede acceder al mismo tiempo)
🧮 Sistemas gestores de bases de datos - Definición:
Un Sistema Gestor de Bases de Datos (en adelante lo llamaremos SGBD), es un conjunto de programas o herramientas que sirven para definir crear manipular y mantener una base de datos. Además ofrecen otras series de utilidades como pueden ser:
- Optimizar el rendimiento
- Crear estadísticas de uso
- Logs (guardar mensajes de errores)
- Otros
Arquitectura de un SGDB:
Arquitectura de 3 niveles propuesta por el comité ANSI-SPARC.
1 - Nivel externo o de visión (cómo se ve la base de datos cuando accedemos a ella)
2 - Nivel conceptual (la organización y estructura de la base de datos)
3 - A nivel interno o físico (los archivos y datos de la base de datos)
* Los dos primeros niveles son niveles LOGICOS, y el tercer nivel es un nivel FISICO
Independencia de los datos:
Capacidad para modificar algún aspecto de uno de los tres niveles anteriores sin que haya que hacer cambios en los otros dos niveles.
- Independencia lógica (capacidad de modificar el nivel conceptual sin tener que cambiar nada del nivel externo)
- Independencia física (posibilidad para modificar el nivel interno sin tener que cambiar nada del nivel conceptual)
Funciones de los SGBD:
- Permitir a los usuarios acceder a la base de datos y poder modificarla de forma sencilla
- Garantizar las reglas y restricciones que los programadores hayan implantado
- Sistema de seguridad que garantice el acceso a la información a solo aquellos usuarios que dispongan de autorización
- Garantizar que se realicen correctamente las transacciones y si hay algún fallo que el sistema sea capaz de corregirlo
- Debe disponer de herramientas para llevar un registro o estadísticas del número de operaciones efectuadas quien las efectuó cuando se efectuaron y si hubo accesos indebidos
- Ser capaz de gestionar operaciones en el que accedan o quieran cambiar un dato dos usuarios a la vez
- Capacidad de poder gestionar más de una base de datos
- Disponer de un diccionario de datos
📓 El diccionario de datos:
Es una estructura que está dentro de la base de datos que organiza cómo están almacenados y donde los diversos objetos (objetos: tablas usuarios paquetes índices vistas...) (ver dibujo)
#️⃣ Lenguaje del SGBD:
Para que los programadores puedan realizar las diversas operaciones sobre la base de datos, necesitan un lenguaje de programación que en este caso es SQL. Structured query language.
▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂
🟨 COMANDOS SQL BÁSICOS
Lenguaje de DEFINICIÓN de datos DDL - (CAD)
📃 CREATE (crear objeto)
✏️ ALTER (modificar objeto)
🗑️ DROP (borrar objeto)
Lenguaje de MANIPULACIÓN de datos DML - (SIUD)
✋ SELECT (para obtener datos de una BBDD)
💉 INSERT (insertar datos en tabla)
🔄 UPDATE (modificar datos de una tabla)
🗑️ DELETE (eliminar registros de una tabla)
Lenguaje de CONTROL de datos DCL - (GR)
👑 GRANT (dar permisos a usuario)
❌ REVOKE (quitar permisos a usuario)
Lenguaje de CONTROL de transacciones TCL - (CR)
💾 COMMIT (guardar cambios correctos)
↩️ ROLLBACK (deshacer cambios hechos)
▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂
3 usuarios del SGBD:
♛ El administrador
♜ Programadores
♟ Usuarios finales
ADMINISTRADOR (DBA): normalmente suele haber uno solo, aunque podría haber más en la empresa.
- Instalar y crear las bases de datos
- Crear y mantener el esquema
- Crear y mantener las cuentas de usuarios
- Colaborar en formación de usuarios
- Arrancar y parar el SGBD
- Colaborar en la identificación y configuración de la ubicación y tamaños de los archivos que se necesitan
- Implementar normas de uso y cómo se debe acceder
- Supervisar los cambios que van realizando los usuario de la Base de Datos y ayudarles ante cualquier problema o incidencia
- Realizar copias de seguridad de la Base de Datos cada cierto TIEMPO
- Restablecer la Base de Datos desde COPIAS de SEGURIDAD si ha habido alguna pérdida de información
- Analizar los archivos de LOGS de ERRORES para detectar anomalías, intentos de accesos indebidos, etc
PROGRAMADORES:
Son usuarios que pueden crear sus propios OBJETOS dentro de la BASE DE DATOS. Sólo van a poder realizar aquellas operaciones a las que el administrador de la base de datos les haya dado PERMISO PREVIAMENTE.
LOS USUARIOS FINALES:
Son usuarios finales los que básicamente sólo van a poder introducir o consultar datos. No van a poder cambiar ni el diseño ni la estructura de la base de datos.
╮
├╸🔳 La opción COMMIT está implícita en estos comandos
╯
╮
├╸📝
╯
╮
├╸👤
╯
╮
├╸💾
╯
basicCommands
T2_BBDD
🔶 BASES DE DATOS TEMA 2 - DISEÑO CONCEPTUAL Y LÓGICO DE LAS BBDD
DIAGRAMAS ENTIDAD RELACIÓN (E/R):
El DISEÑO CONCEPTUAL de una base de datos recoge los requerimientos definidos por usuarios, los hechos y reglas que se implementarán en la BBDD. Para trabajar con este esquema, se usa el MODELO CONCEPTUAL, representado por los diagramas ENTIDAD RELACIÓN.

▭ ENTIDADES (tablas)
◯ Atributos (columnas)
◯ CLAVE PRIMARIA (columnas)
Datos (datos en columnas)
◇ relaciones (acciones entre sí)
(0,1) Participaciones
1:1 Cardinalidades
MODELO CONCEPTUAL, DIAGRAMAS E/R:
El Modelo Conceptual, también llamado Entidad Relación (E-R), fue propuesto por PETER CHEN en 1976 para la representación conceptual de los problemas del mundo real. En 1988 el ANSI (American National Standars Institute) lo seleccionó como MODELO ESTÁNDAR.
ELEMENTOS DEL DIAGRAMA:
▭ ENTIDADES:
Representación gráfica de objetos de los que se guarda información. Una ENTIDAD se convierte en una TABLA.
Se representa en MAYÚSCULAS y dentro de un RECTÁNGULO.
◯ ATRIBUTOS / CAMPOS / COLUMNAS:
Son las unidades de información que describen propiedades en las ENTIDADES.
3 TIPOS DE ATRIBUTOS:
Atributo Alternativo: Cualquier atributo de una ENTIDAD.
- Se representa con la primera letra Mayúscula y dentro de una ELIPSE.
- Un atributo con múltiples valores se representará con 2 ELIPSES.
Atributo Principal / Clave Primaria / PRIMARY KEY : Aquel atributo que identifica de forma ÚNICA a cada OCURRENCIA de una ENTIDAD.
- Se presenta en MAYÚSCULAS y subrayado, dentro de una ELIPSE.
- No puede contener valores NULOS (ausencia de valores. 0 es un valor válido)
- No puede variar con el tiempo
Atributo Foráneo / Clave Ajena : Es el ATRIBUTO o CONJUNTO DE ATRIBUTOS de una ENTIDAD que forman la CLAVE PRIMARIA en OTRA ENTIDAD. Las claves ajenas van a representar las relaciones entre tablas.
- Se presenta subrayado con línea discontinua (en mis imágenes se representa tachado) dentro de una ELIPSE.
CONCEPTOS ASOCADOS A LOS ATRIBUTOS:
- Valor / Dato -> Son los datos que se guardan en ese atributo
Ejemplo: El atributo Nombre de la entidad ALUMNOS puede ser Pepe.
- Dominio -> Es el conjunto de posibles valores que pueden tomar ese atributo (o rango de valores posibles)
Ejemplo: Para el atributo Nombre , su dominio va a ser una combinación de letras entre la A y la Z.
Ejemplo: Para el atributo Matriculado , su dominio viene definido como el conjunto de valores SI o NO.
OCURRENCIAS / REGISTROS:
La fila de datos de una ENTIDAD (tabla), es decir, todos los datos de una fila (numeradas en orden ascendente).

EJEMPLO sobre la tabla anterior:
diríamos que es un Diagrama de Entidad/Relación con 2 ENTIDADES, con 5 ATRIBUTOS la primera 3 ATRIBUTOS y la segunda. 1 de los ATRIBUTOS de cada ENTIDAD debe ser CLAVE PRIMARIA (siempre), especificando cuales son. Por último, 8 REGISTROS (OCURRENCIAS) de una de las ENTIDADES:
ENTIDADES: ALUMNOS y USUARIOS
5 ATRIBUTOS DE ALUMNOS: DNI, Nombre, Apellido, Edad y Residencia
3 ATRIBUTOS DE USUARIOS: Nombre, EMAIL y Contraseña
REGISTROS DE ALUMNOS: (5 atributos por cada registro)
- 5435346-H, David, Arias, 25, Cádiz
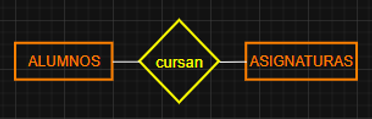
◇ RELACIONES:
La UNIÓN entre 2 o más ENTIDADES, suele definir una acción que las relaciona.
Se representan mediante un ROMBO con un VERBO en su interior.

El diagrama anterior se puede leer/interpretar de dos formas, bidireccionalmente:
- Los ALUMNOS cursan ASIGNATURAS
- Las ASIGNATURAS son cursadas por los ALUMNOS
◇º GRADO de una RELACIÓN:
Designa el número de ENTIDADES que participan en una RELACIÓN. Hay de varios tipos según el número.
- RELACIONES de GRADO 1 o REFLEXIVAS: Relacionan 1 ENTIDAD consigo misma.
- RELACIONES de GRADO 2 o BINARIAS: Relacionan 2 ENTIDADES.
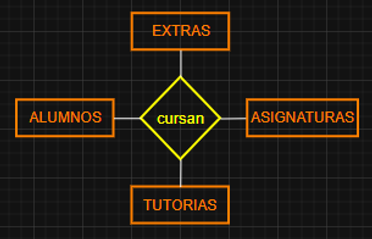
- RELACIONES de GRADO 3 o TERNARIAS: Relacionan 3 ENTIDADES.

- RELACIONES de GRADO 4 o N-ARIAS: Relacionan + de 3 ENTIDADES (poco habituales).
_____________________________________________________________________________________________________________
( ) PARTICIPACIONES (MÍNIMAS y MÁXIMAS):
▭ ENTRE ENTIDADES Y RELACIONES
Indican el NÚMERO MÍNIMO y MÁXIMO de veces que la RELACIÓN puede estar ASOCIADA a una ENTIDAD. Podemos tener las siguientes:
(0,1) - MIN: cero MAX: 1
(1,1) - MIN: 1 MAX: 1
(0,N) - MIN: cero MAX: muchos
(1,N) - MIN: 1 MAX: muchos
Dentro de cada PARÉNTESIS y divididos por "," hay 2 valores, siendo el PRIMERO el valor MÍNIMO posible, y el segundo valor, el MÁXIMO posible.
VALOR 0 : Representa CERO / NINGUNO
VALOR 1 : Representa 1
VALOR N: Representa "ANY", un número a partir de 2 (concepto MUCHOS)
VALOR M: Al igual que N, representa un número a partir de 2 (concepto MUCHOS), pero se usa cuando hay dos ENES en una participación, para no llevar a la confusión de pensar que cada N representa un mismo valor. M lo que hace es marcar la diferencia de que puede ser un valor distinto.
_____________________________________________________________________________________________________________
CARDINALIDAD DE UNA RELACIÓN:
◇ SOBRE RELACIONES indican la suma de los valores MÁXIMOS de las ENTIDADES asociadas a esta RELACIÓN.
SIN PARÉNTESIS y divididos por ":", hay 2 valores, siendo el PRIMERO el valor MÁXIMO de una ENTIDAD, y el otro valor, el MÁXIMO de la otra ENTIDAD. Podemos encontrar las siguientes combinaciones:
1:1 1:N N:M
1:1:1 1:1:N 1:N:M N:N:M
_____________________________________________________________________________________________________________
➨ EN UNIONES (VALORES MÁXIMOS)
Si el valor MÁXIMO es 1, se dibujará una LÍNEA CONTÍNUA: ━━━━━
Si el valor MÁXIMO es N, se dibujará una LÍNEA FLECHA: ━━━━━▶
_____________________________________________________________________________________________________________
EJEMPLO SENCILLO:
En este caso, se nos dice que, en un estudio biológico, una PERSONA (HOMBRE) puede ser padre de algún HIJO.
Un padre puede tener, cero, uno, o varios hijos. Y un hijo tiene que tener necesariamente un solo padre biológico. POR TANTO:
Un HOMBRE puede tener MIN: 0 hijos, MAX: varios hijos
Un HIJO puede serlo de MIN: 1 padre, MAX; 1 padre
Y con esa lógica, se representan las uniones con flecha hacia las RELACIONES que tienen un MAX de MUCHOS.

( ) CARDINALIDAD DE UNA RELACIÓN:
Se calcula a través de las participaciones que hay entre las RELACIONES.
Se obtiene con los VALORES MÁXIMOS de las participaciones existentes.
Usando el ejemplo anterior, donde tenemos (1.1) para la ENTIDAD HOMBRES y (0.N) para la ENTIDAD HIJOS, cogiendo el valor MÁXIMO de cada no, nos da como resultado 1:N en la cardinalidad de la RELACIÓN:
NOTA: Nótese que se representa sin paréntesis y separado por ":" en lugar de un punto o una coma.
NOTA: Los valores se representan siempre de MENOR a MAYOR, no en el orden de disposición de las ENTIDADES en el diagrama.
NOTA: En el caso de que la suma de AMBOS valores MÁXIMOS fuera N, se representará como N:M uno de los dos, normalmente el segundo.
Más EJEMPLOS:

CARDINALIDAD DE RELACIONES TERNARIAS:
Base da datos de empresas, empresas auditoras y los informes que se obtienen de cuando una empresa hace auditorías de otras empresas
(1,1) en EMPRESAS = Un informe concreto y una auditoría concreta ¿a cuántas empresas puede pertenecer? sólo va a poder pertenecer a una empresa ya que tendrá su código de informe que irá asociado a una empresa.
(1,N) en INFORMES= Una empresa concreta y una auditoría concreta ¿cuántos informes puede hacer? mínimo ha tenido que hacerle una y puede que haya alguna empresa a la que le hayan hecho más de un informe.
(1,1) en AUDITORIAS = Una empresa concreta y un informe concreto ¿cuántas auditorías han podido realizarlo? sólo lo habrá podido hacer una auditora en concreto (mínimo y máximo).
SUMA DE MÁXIMOS: 1:1:N

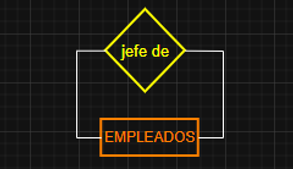
CARDINALIDAD DE RELACIONES REFLEXIVAS:
Todos los empleados tienen UN jefe y sólo UN JEFE menos el Presidente de la Empresa, que no tiene superiores por encima.
(1,N) = Aquí la lectura es la siguiente: Un "empleado que es jefe de empleados", puede tener a su cargo 1 o varios empleados.
(0,1) = Y en la dirección opuesta, la lectura es: Un "empleado" (todos) puede tener, o ningún jefe (si ese miembro de la plantilla es el presidente) o 1 solo jefe, en el caso del resto, que tendrá por lo menos un superior.
SUMA DE MÁXIMOS: 1:N
ATRIBUTOS DE UNA RELACIÓN:
Normalmente las relaciones NO tienen ATRIBUTOS, pero se dan situaciones en las que el atributo va a depender de las 2 o + ENTIDADES.
En la imagen podemos ver que el ATRIBUTOS "Nota" está ligado a la RELACIÓN. ¿Por qué? porque el ATRIBUTOS "Nota" depende del ALUMNO y de la ASIGNATURA para que se pueda definir una cantidad. No podríamos ponerlo como ATRIBUTO de ALUMNO o de ASIGNATURA ya que es necesario conocer a qué ALUMNO pertenece la Nota, y a qué ASIGNATURA, sin una de las dos la nota no tiene sentido.

DEL MODELO ENTIDAD/RELACIÓN AL MODELO "PASO A TABLAS":
Esquema-Resumen con todas las posibles combinaciones y resultados.
NOTA: Los atributos tachados simbolizan las CLAVES AJENAS, que en realidad se debería representar con SUBRAYADO DISCONTÍNUO.
Se recuerda que una CLAVE AJENA es una CLAVE PRIMARIA de una ENTIDAD cuando se copia a otra ENTIDAD según las reglas.

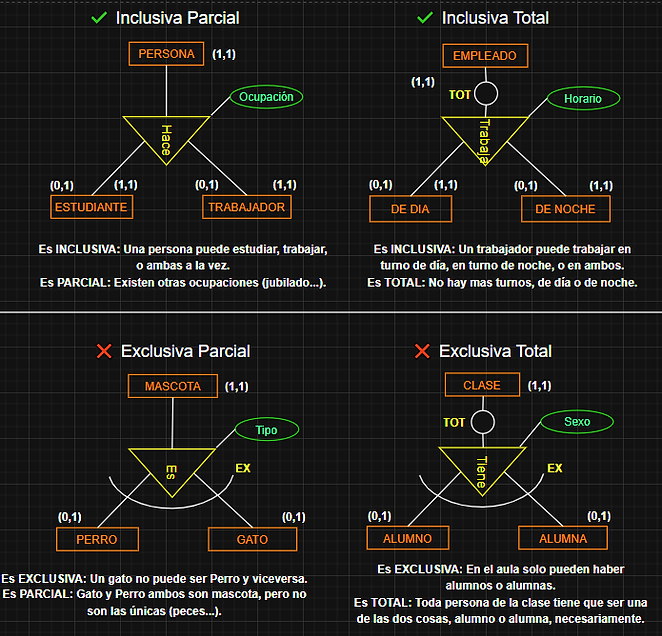
RELACIONES JERÁRQUICAS:
Las hay de 4 tipos. A continuación se explican con ejemplos:
📊 BASES DE DATOS - EJERCICIOS PRÁCTICOS DE DIAGRAMAS E/R
EJERCICIO A:
Una empresa vende productos a varios clientes. Se necesita conocer los datos personales de los clientes (nombre, apellidos, DNI, dirección y fecha de nacimiento). Cada producto tiene un nombre y un código, así como un precio unitario. Un cliente puede comprar varios productos a la empresa, y un mismo producto puede ser comprado por varios clientes.
Los productos son suministrados por diferentes proveedores. Se debe tener en cuenta que un producto sólo puede ser suministrado por un proveedor, y que un proveedor puede suministrar diferentes productos. De cada proveedor se desea conocer el NIF, nombre y dirección.
👆 Clicar imagen para ampliar

EJERCICIO B:
Se desea informatizar la gestión de una empresa de transportes que reparte paquetes por toda España. Los encargados de llevar los paquetes son los camioneros, de los que se quiere guardar el dni, nombre, teléfono, dirección, salario y población en la que vive. De los paquetes transportados interesa conocer el código de paquete, descripción, destinatario y dirección del destinatario. Un camionero distribuye muchos paquetes, y un paquete sólo puede ser distribuido por un camionero.
De las provincias a las que llegan los paquetes interesa guardar el código de provincia y el nombre.
Un paquete sólo puede llegar a una provincia. Sin embargo, a una provincia pueden llegar varios paquetes.
De los camiones que llevan los camioneros, interesa conocer la matrícula, modelo, tipo y potencia.
Un camionero puede conducir diferentes camiones en fechas diferentes, y un camión puede ser conducido por varios camioneros.
👆 Clicar imagen para ampliar

EJERCICIO C:
Se desea diseñar la base de datos de un Instituto. En la base de datos se desea guardar los datos de los profesores del Instituto (DNI, nombre y teléfono). Los profesores imparten módulos, y cada módulo tiene un código y un nombre. Cada alumno está matriculado en uno o varios módulos. De cada alumno se desea guardar el número de expediente, nombre, apellidos y fecha de nacimiento. Los profesores pueden impartir varios módulos, pero un módulo sólo puede ser impartido por un profesor. Cada curso tiene un grupo de alumnos, uno de los cuales es el delegado del grupo.
👆 Clicar imagen para ampliar

EJERCICIO D:
A un concesionario de coches llegan clientes para comprar automóviles. De cada coche interesa saber la matrícula, modelo, marca y color. Un cliente puede comprar varios coches en el concesionario. Cuando un cliente compra un coche, se le hace una ficha en el concesionario con la siguiente información: dni, nombre, apellidos, dirección y teléfono.
Los coches que el concesionario vende pueden ser nuevos o usados (de segunda mano). De los coches nuevos interesa saber el número de unidades que hay en el concesionario. De los coches viejos interesa el número de kilómetros que lleva recorridos.
El concesionario también dispone de un taller en el que los mecánicos reparan los coches que llevan los clientes. Un mecánico repara varios coches a lo largo del día, y un coche puede ser reparado por varios mecánicos. Los mecánicos tienen un DNI, nombre, apellidos, fecha de contratación y salario.
Se desea guardar también la fecha en la que se repara cada vehículo y el número de horas que se tardado en arreglar cada automóvil.
👆 Clicar imagen para ampliar

EJERCICIO E:
Se desea informatizar la gestión de una tienda informática. La tienda dispone de una serie de productos que se pueden vender a los clientes.
De cada producto informático se desea guardar el código, descripción, precio y número de existencias. De cada cliente se desea guardar el código, nombre, apellidos, dirección y número de teléfono.
Un cliente puede comprar varios productos en la tienda y un mismo producto puede ser comprado por varios clientes. Cada vez que se compre un artículo quedará registrada la compra en la base de datos junto con la fecha en la que se ha comprado el artículo.
La tienda tiene contactos con varios proveedores que son los que suministran los productos. Un mismo producto puede ser suministrado por varios proveedores. De cada proveedor se desea guardar el código, nombre, apellidos, dirección, provincia y número de teléfono.
👆 Clicar imagen para ampliar

ejercicios_diagramasE/R
🧱 BASES DE DATOS TEMAS 3 y 4 - DISEÑO FÍSICO y EDICIÓN DE DATOS EN BBDD
ORACLE SQL DEVELOPER:
Oracle SQL Developer es un programa gratuito creado por Oracle que te permite trabajar con bases de datos Oracle. Imagina que tienes una gran biblioteca llena de libros (la base de datos), y necesitas encontrar información específica, organizar los libros o incluso escribir tus propios libros. Oracle SQL Developer es como la herramienta que te ayuda a hacer todo eso de manera fácil y organizada. Puedes usarlo para ver y entender cómo está organizada la información en la base de datos, escribir comandos para obtener la información que necesitas, crear programas para hacer tareas automáticamente, encontrar y corregir errores, y también para mantener y administrar la base de datos. Es como tener un conjunto de herramientas completo para trabajar con información de manera eficiente.
DESCARGAR ÚLTIMA VERSIÓN:
🔽 https://www.oracle.com/database/sqldeveloper/technologies/download/
DESCARGA E INSTALACIÓN PASO POR PASO:
🎞️ https://www.youtube.com/watch?v=1GwUi2sfUas
USUARIOS ADMINISTRADORES POR DEFECTO:
SYS
SYSTEM (cuenta auxiliar)
CREAR UNA CONEXIÓN:
La primera conexión se hace siempre con alguno de los usuarios administradores que vienen configurados por defecto. Una vez realizada esta primera conexión, habilitaremos nuevos usuarios con los que trabajaremos en las bases de datos. De hacer desde una cuenta de administrador directamente, podemos cometer errores o realizar cambios en la configuración del programa que nos obliguen a una reinstalación completa, con la posibilidad de una pérdida de datos irreparable.
Ejemplo de primera conexión:
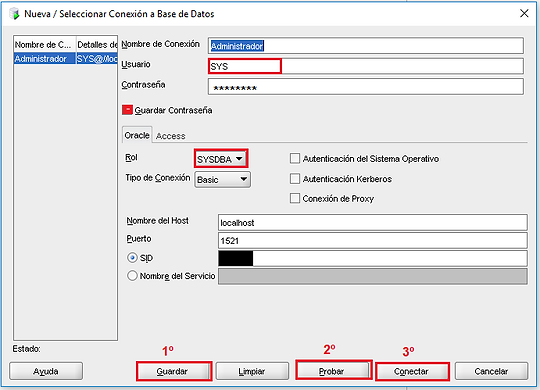
Nombre de conexión: Administrador
Usuario: SYS (administrador por defecto)
Contraseña: ****** (la que haya sido introducida)
* Marcamos guardar contraseña para que no vuelva a preguntar *
Rol: SYSDBA (por tratarse de un administrador)
Tipo de Conexión: Basic
Nombre del Host: localhost (en este caso es una base de datos local, por lo que no nos conectamos fuera de la máquina, pero podría ser el caso, para una administración remota)
Puerto: 1521 (por defecto)
SID: ****** (System IDentifier. El que se haya configurado)
Una vez introducidos los campos requeridos, en el siguiente orden, 1º GUARDAMOS los campos, 2º PROBAMOS la conexión, y si es EXITOSA, terminamos el proceso con 3º CONECTAR.
ERRORES COMUNES:
Si la primera vez que intentamos una conexión nos tira ERROR, una posible solución es:
1 - Cerrar la Máquina Virtual
2 - Ir a Configuración de la misma
3 - En la sección de RED, pestaña Adaptador 1, asegurarnos que se encuentra marcado "Habilitar adaptador de red", poner la opción de "NAT" y después poner la opción de "Adaptador Puente". Y Aceptar.
4 - Volver a ejecutar la Máquina Virtual y probar la conexión de nuevo.

Otro ERROR que se puede generar cuando damos nuestros primeros pasos con Oracle SQL Developer es el que salta con el nombre:
java.lang.NullPointerException
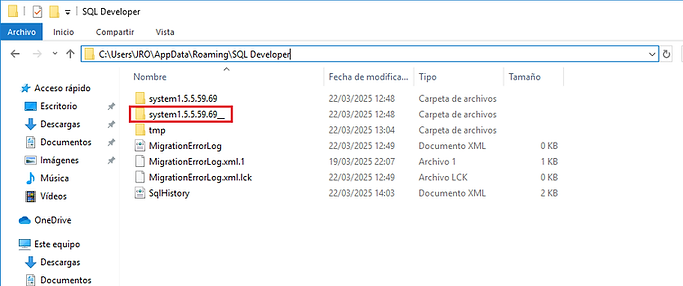
Este se puede solucionar, cerrando SQL Developer y navegando hasta la ruta:
C:\Users\[usuario_del_sistema]\AppData\Roaming\SQL Developer
Ahora, a la carpeta llamada "system" seguida de unos números, le cambiaremos el nombre (por ejemplo, añadiendo dos guiones bajos).
Volvemos a iniciar SQL Developer y el programa creará una nueva carte "system" con los parámetros por defecto, arreglándose en el proceso el error anterior.
NOTA: Podríamos haber perdido cierta información, que se encontrará en la carpeta antigua, desde la cual podremos tratar de migrarla de forma ordenada y gradual.

VISALIZAR NÚMEROS DE LÍNEA:

ESPACIO DE TRABAJO:

✔️ CREAR NUEVO USUARIO:
Todavía como usuario administrador, ejecutamos en la Zona de Ejecución las siguientes líneas una a una con el botón de "▶ Ejecutar Sentencia" o con la tecla F9:
CREATE USER usuario IDENTIFIED BY contraseña (Crear usuario nuevo con nombre y contraseña)
GRANT CONNECT TO usuario (Otorgar permisos de conexión al usuario nuevo)
GRANT RESOURCE TO usuario (Otorgar permiso para crear tablas al usuario nuevo)
❌ ELIMINAR USUARIO:
DROP USER usuario CASCADE;


Si hemos hecho correctamente los pasos anteriores, podemos configurar la conexión del nuevo usuario como vemos en la imagen.
La contraseña debe ser la introducida en las líneas de código para el nuevo usuario.
* Marcamos guardar contraseña para que no vuelva a preguntar *
A diferencia de antes, ahora el ROL será por defecto "default" al ser un usuario NO administrador.
----------------------------------------------------------------------------------------------------------------------------------
ATAJOS DE TECLADO:
[F8] (Ver el Historial de comandos SQL)
[F9] (▶ Ejecutar Sentencia)
[F11] (COMMIT, o confirmar y guardar los últimos cambios)
[F12] (ROLLBACK, o deshacer los últimos cambios sin guardar)
[CTRL] + [D] (Limpiar Zona de Ejecución)
----------------------------------------------------------------------------------------------------------------------------------
CREAR TABLAS:
Ya desde el nuevo usuario (vemos la pestaña "Mike") ejecutamos las líneas necesarias en cada caso para crear una tabla nueva.
A continuación, un ejemplo sencillo:
CREATE TABLE Alumnos
(
DNI VARCHAR2(8),
LETRA_DNI CHAR(1),
NOMBRE_APELL VARCHAR2(40),
FECHA_NACIM DATE,
EDAD NUMBER2(2),
PESO NUMBER(5,2),
DESCRIPCION LONG
);
NOTA: observar la apertura de paréntesis "(" después del nombre de la tabla y al final de los parámetros, con el cierre ");". También observamos que el último parámetro, en este caso LONG, con termina con "," coma, por que termina con el cierre ");".

REFRESCAR:
Los cambios realizados en la base de datos no se visualizarán en el árbol de contenido (izquierda) hasta que no se "refresque" la información. Podemos hacerlo con el botón derecho sobre la tabla y a "refrescar".
AL GENERAR OBJETOS E INTRODUCIR DATOS, TENER EN CUENTA:
- Los nombres de tablas y columnas admiten hasta 30 caracteres
- El primer caracter tiene que ser SIEMPRE una letra (si es un número, dará error)
- No se pueden usar nombres reservados a comandos (por ejemplo CREATE)
- En el nombre NO pueden haber espacios. Como norma no escrita, se reemplazan por "_"
- No se deben usar tildes
PARA VER TABLA "DUMMY" DE PRUEBA:
SELECT * FROM DUAL
PARA VER LA TABLA CREADA:
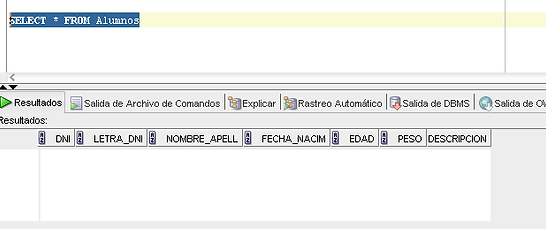
SELECT * FROM Alumnos

T3_BBDD
🟨 BASES DE DATOS - COMANDOS ORACLE SQL PARA OPERAR BASES DE DATOS
COMANDOS Y SÍMBOLOS:
* (Significa TODO)
% (Significa cualquier cadena de 1 o más caracteres)
_ (Significa 1 caracter cualquiera)
🟧 CREAR TABLA:
CREATE TABLE tabla
(
columna tipo_dato,
columna tipo_dato,
columna tipo_dato
);
🗑️ ELIMINAR TABLAS:
DROP TABLE tabla (Eliminar tabla. Tarda más cuando hay muchos datos. Permite ROLLBACK)
TRUNCATE TABLE tabla (Eliminar tabla. Es más rápido. NO permite ROLLBACK)
📑 TIPOS DE DATOS al crear tabla:
columna NUMBER, (Permite introducir un valor numérico de hasta 38 dígitos por defecto)
columna NUMBER(1), (Permite introducir un valor numérico de hasta 1 dígito, del 0 al 9)
columna NUMBER(2), (Permite introducir un valor numérico de hasta 2 dígitos, del 0 al 99)
columna NUMBER(5,2), (Permite introducir un valor numérico de hasta 5 dígitos con 2 decimales, del 0 al 999.99) <-usar punto
columna CHAR, (Permite introducir un valor de hasta 3 caracteres por defecto)
columna CHAR(1), (Permite introducir un valor de hasta 1 caracter)
columna CHAR(8), (Permite introducir un valor de hasta 8 caracteres)
columna VARCHAR2, (Permite introducir números y letras hasta 4.000 bytes en versiones anteriores a Oracle 12c)
columna VARCHAR2, (Permite introducir números y letras hasta 32.767 bytes en versiones posteriores a Oracle 12c)
columna VARCHAR2(1), (Permite introducir números y letras hasta en 1 espacio)
columna VARCHAR2(8), (Permite introducir números y letras hasta en 8 espacios)
columna LONG, (Permite introducir un texto largo. Cuando VARCHAR2 se queda corto. OBSOLETO?)
columna CLOB, (Permite introducir un texto largo. Cuando VARCHAR2 se queda corto)
columna DATE, (Permite introducir una fecha en el formato DD/MM/YY)
🛂 CONTROL DE ACTIVIDAD:
COMMIT (Confirmar y guardar última acción. También con [F11]. No es necesario con comandos DDL)
ROLLBACK (Deshacer última acción. También con [F12])
🔑 ESTABLECER UNA CLAVE PRIMARIA CREANDO TABLA:
columna tipo_dato PRIMARY KEY, (Establece Clave Primaria a nivel de CAMPO)
CONSTRAINT PK_columna PRIMARY KEY (columna), (Establece Clave Primaria a nivel de TABLA. Se coloca AL FINAL)
🔑 ESTABLECER UNA CLAVE PRIMARIA A POSTERIORI (las 2 líneas):
ALTER TABLE tabla
ADD CONSTRAINT PK_columna PRIMARY KEY (columna);
❌ ESTABLECER CONDICIONANTE NOT NULL CREANDO TABLA:
columna tipo_dato NOT NULL, (Establece que el dato se obligatorio a nivel de CAMPO)
CONSTRAINT NN_tabla_columna NOT NULL (columna), (Establece que el dato se obligatorio a nivel de TABLA)
❌ ESTABLECER CONDICIONANTE NOT NULL A POSTERIORI (las 2 líneas):
ALTER TABLE tabla
MODIFY columna INT CONSTRAINT NN_tabla_columna NOT NULL;
1️⃣ ESTABLECER CONDICIONANTE UNIQUE CREANDO TABLA (NO se puede usar con el tipo de dato NUMBER):
columna tipo_dato UNIQUE, (Establece que los valores de esta columna NO se pueden repetir a nivel de CAMPO)
CONSTRAINT UQ_columna UNIQUE (columna), (Establece que los valores de esta columna NO se pueden repetir a nivel de TABLA)
1️⃣ ESTABLECER CONDICIONANTE UNIQUE A POSTERIORI (las 2 líneas):
ALTER TABLE tabla
ADD CONSTRAINT UQ_columna UNIQUE (columna);
👁️ LISTAR INFORMACIÓN DE TODA LA TABLA:
SELECT * FROM tabla (Muestra TODA la info de la tabla)
DESC tabla (Muestra alguna info de la tabla, la describe)
SELECT * FROM ALL_TABLES (Muestra METADATOS de todas las tablas de la base de datos)
SELECT * FROM ALL_CONSTRAINTS (Muestra METADATOS de todas las restricciones de la base de datos)
👁️ LISTAR INFORMACIÓN CONCRETA:
SELECT columna/s FROM tabla;
SELECT columna/s FROM tabla WHERE columna1 = 'valor1'
👁️ VER METADATOS / LOGS DE ACTIVIDAD:
DBA_tabla (Solo ADMIN)
ALL_tabla (Usuario cualquiera)
⬜ INSERTAR VALORES EN COLUMNAS DE TABLA (entre paréntesis, separados por coma. Entre 'comillas simples' los textos, números no):
INSERT INTO tabla VALUES (00000,'abcde');
⬜ INSERTAR SOLO ALGUNOS VALORES EN COLUMNAS DE TABLA:
INSERT INTO tabla (columna1,columna2) VALUES (00000,'abcde');
🆑 BORRAR DATOS DE LA TABLA:
DELETE FROM tabla WHERE columna1 = 'valor1';
☑️ ESTABLECER CONDICIONANTES CHECK BETWEEN/IN CREANDO TABLA:
columna tipo_dato CHECK (columna BETWEEN valor_bajo AND valor_alto), (Establece valor mínimo y máximo para una columna)
columna tipo_dato CHECK (columna IN (valor1,valor2)), (Establece valores válidos para una columna)
☑️ ESTABLECER CONDICIONANTES CHECK BETWEEN/IN A POSTERIORI (2 líneas para cada uno):
ALTER TABLE tabla
ADD CONSTRAINT CK_columna CHECK (columna BETWEEN valor_bajo AND valor_alto);
ALTER TABLE tabla
ADD CONSTRAINT CK_columna CHECK (columna IN (valor1,valor2));
#️⃣ OPERADORES DE COMPARACIÓN:
= (Igual a)
> (Mayor que)
>= (Mayor o igual que)
< (Menor que)
>= (Menor o igual que)
!= (Distinto a)
<> (Distinto a)
% (Cualquier cadena de 1 o más caracteres)
_ (1 caracter cualquiera)
☑️ ESTABLECER CONDICIONANTES CHECK LIKE(CON EJEMPLOS. Ojo a las comillas simples ' '):
CONSTRAINT CK_columna CHECK (columna LIKE 'M%'); (Los valores de la columna dada, tienen que empezar por la letra M)
CONSTRAINT CK_columna CHECK (columna LIKE '20__'); (Los valores de la columna dada, tienen que empezar por 20 y permite 2 caracteres más)
CONSTRAINT CK_columna CHECK (columna LIKE '_Z_'); (Los valores de la columna dada, tienen que contener la letra Z)
🗝️ ESTABLECER UNA CLAVE AJENA SIEMPRE A POSTERIORI:
- Creando tablas, las que contengan CLAVE AJENA se crean siempre al final
- Borrando tablas, primero se borran las que tengan CLAVE AJENA
- Las columnas se duplican en ambas tablas y luego se ENLAZAN. Deben tener el mismo tipo de datos
CREATE TABLE tabla2
CONSTRAINT FK_columna1 FOREIGN KEY (columna1) REFERENCES tabla1 (columna1); (La columna1 de tabla1 se pone de CLAVE AJENA en tabla2)
Ejemplo al crear la tabla ARTICULOS:
CREATE TABLE Articulos
CONSTRAINT FK_DNI FOREIGN KEY (DNI) REFERENCES Vendedores (DNI); (La columna DNI de VENDEDORES se pone de CLAVE AJENA en ARTICULOS)

#️⃣ CONSTRAINT TYPES:
C (Check)
P (Primary key)
R (foReign key)
U (Unique)
🔄 HACER CAMBIOS CON UPDATE (modificar DATOS con condicionantes):
UPDATE tabla SET columna = columna + valor WHERE columna BETWEEN valor_bajo AND valor_alto;
Ejemplos:
UPDATE Empleados SET Salario = Salario + 100 WHERE Edad BETWEEN 45 AND 55; (Sumar +100€ de salario a los empleados entre 45 y 50 años)
UPDATE Empleados SET Salario = Salario + 100 WHERE Ciudad IN ('Madrid'); (Sumar +100€ de salario a los empleados que vivan en Madrid)
✏️ HACER CAMBIOS CON ALTER (+ 7 VARIANTES):
ALTER TABLE tabla
ADD columna; (Añadir columna nueva)
MODIFY columna; (Modificar la columna dada)
DROP COLUMN columna; (eliminar la columna dada
ADD CONSTRAINT nombre_restricción; (Añadir restricción con el nombre_restricción dado)
DROP CONSTRAINT nombre_restricción; (Eliminar restricción con el nombre_restricción dado)
DISABLE CONSTRAINT nombre_restricción; (Deshabilitar la restricción con el nombre_restricción dado)
ENABLE CONSTRAINT nombre_restricción; (Habilitar la restricción con el nombre_restricción dado)
Ejemplos:
ALTER TABLE Empleados
MODIFY Nombre VARCHAR2(40); (Aumentar el número de caracteres de la columna Nombre a 40)
ALTER TABLE Empleados
ADD Telefono VARCHAR2(9) UNIQUE; (Crear nueva columna Telefono con espacio para 9 números, y que no se puedan repetir)
ALTER TABLE Empleados
ADD CONSTRAINT CK_Salario CHECK (Salario BETWEEN 1000 AND 1500); (En la columna Salario, solo dejará meter valores entre 1000 y 1500)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
EJEMPLO PRÁCTICO CON TODAS LAS VARIANTES:

🟧 CREAR TABLA AMPLEADOS:
NOTA: Primero se crea la tabla Portatiles, que hace enlaza su CLAVE PRIMARIA Cod_PC a Empleados como CLAVE AJENA.
NOTA: Introduce el texto manualmente, copiar y pegar desde aquí puede importar caracteres invisibles que invaliden el código)
CREATE TABLE Portatiles
(
Cod_PC VARCHAR2(4) UNIQUE NOT NULL,
Fecha DATE NOT NULL,
Marca VARCHAR2(15) NOT NULL CHECK (Marca IN ('HP','Lenovo')),
Descripcion LONG,
CONSTRAINT PK_Cod_PC PRIMARY KEY (Cod_PC), <--(no es necesaria, ya es UNIQUE)
CONSTRAINT CK_Cod_PC CHECK (Cod_PC LIKE 'C%')
);
CREATE TABLE Empleados
(
DNI VARCHAR2(9) UNIQUE NOT NULL,
Nom_Apell VARCHAR2(40) NOT NULL,
Ciudad VARCHAR2(15) NOT NULL CHECK (Ciudad IN ('Madrid','Barcelona',Malaga')),
Cod_PC VARCHAR2(4) UNIQUE NOT NULL,
CONSTRAINT PK_DNI PRIMARY KEY (DNI), <--(no es necesaria, ya es UNIQUE)
CONSTRAINT FK_Cod_PC FOREIGN KEY (Cod_PC) REFERENCES Portatiles (Cod_PC)
);
⬜ INTRODUCIR DATOS:
NOTA: Primero metemos los 5 portatiles registrados, uno a uno con cada línea. Comprobamos luego con SELECT * FROM Portatiles.
INSERT INTO Portatiles VALUES ('C001','20/03/25','HP','Buen estado');
INSERT INTO Portatiles VALUES ('C002','20/03/25','HP','Buen estado');
INSERT INTO Portatiles VALUES ('C003','21/03/25','Lenovo','Buen estado');
INSERT INTO Portatiles VALUES ('C004','22/03/25','Lenovo','Rasguños');
INSERT INTO Portatiles VALUES ('C005','23/03/25','Lenovo','Buen estado');
NOTA: Después metemos los 4 empleados. Comprobamos luego con SELECT * FROM Empleados.
INSERT INTO Empleados VALUES ('72485784T','John Wick','Madrid','C001');
INSERT INTO Empleados VALUES ('70348534R','Mike Delta','Madrid','C002');
INSERT INTO Empleados VALUES ('83645434C','Pere Jauvert','Barcelona','C003');
INSERT INTO Empleados VALUES ('69526472S','Juan Civera','Malaga','C004');
🛂 CONFIRMAR DATOS:
COMMIT
✏️ MODIFICAR DNI DEL EMPLEADO JOHN WICK:
UPDATE Empleados
SET DNI = '00000000T'
WHERE Nom_Apell = 'John Wick';
⬜ INTRODUCIR DATOS:
NOTA: Vamos a meter 3 portatiles más, todos de una. Comprobamos luego con SELECT * FROM Portatiles.
NOTA: Al final hay que meter "SELECT * FROM dual;" para que el programa inserte las líneas dadas, si no, no funciona.
INSERT ALL
INTO Portatiles (Cod_PC, Fecha, Marca, Descripcion) VALUES ('C006', TO_DATE('24/03/25','DD/MM/YY'), 'Lenovo', 'Averiado')
INTO Portatiles (Cod_PC, Fecha, Marca, Descripcion) VALUES ('C007', TO_DATE('24/03/25','DD/MM/YY'), 'HP', 'Buen estado')
INTO Portatiles (Cod_PC, Fecha, Marca, Descripcion) VALUES ('C008', TO_DATE('24/03/25','DD/MM/YY'), 'Lenovo', 'Falta una tecla') SELECT * FROM dual;
✏️ ASIGNAR OTRO PORTATIL AL EMPLEADO JOHN WICK:
UPDATE Empleados
SET Cod_PC = 'C006'
WHERE Nom_Apell = 'John Wick';
En este punto se pueden hacer varias pruebas para comprobar la funcionalidad de los CONDICIONANTES.
Si en lugar de asignarle a "John Wick" el portátil "C006", recién introducido en la tabla Portatiles, le asignamos un portátil inventado, como por ejemplo "C009", dará ERROR. También, si le asignamos un portátil ya asignado a otro Empleado, como por ejemplo el "C002", también dará ERROR.
Como hay 2 portátiles averiados, hay que crear una nueva columna en Portatiles que indique si el portátil está operativo para su uso o no.
🟩 CREAR COLUMNA CON ALTER (por defecto indicaremos que todos los portátiles NO están operativos. se pondrán después):
ALTER TABLE Portatiles
ADD Operativo CHAR(2) DEFAULT 'NO' CHECK (Operativo IN ('SI','NO'));
✏️ ACTUALIZAR EL ESTADO DE LOS PORTÁTILES OPERATIVOS:
UPDATE Portatiles SET Operativo = 'SI' WHERE Cod_PC IN ('C001','C002','C003','C004','C005','C007');
SELECT * FROM Portatiles (comprobación)



ASEGURAR QUE NO HAY VALORES NULOS / VALOR NULO SE CONVIERTE EN "NO" (RECOMENDADO):
UPDATE Portatiles
SET Operativo = 'NO'
WHERE Operativo IS NULL;
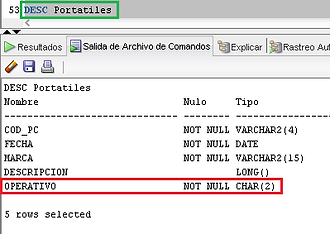
AÑADIR RESTRICCIÓN NOT NULL A LA COLUMNA OPERATIVO:
ALTER TABLE Portatiles
MODIFY Operativo CHAR(2) NOT NULL;
DESC Portatiles (comprobación)
SQL_operarBBDD
🟨 BASES DE DATOS - COMANDOS ORACLE SQL PARA LA REALIZACIÓN DE CONSULTAS
📋 RESUMEN DEL TEMA:
1. Introducción
⬥ Concepto de consulta: uso de SELECT para obtener información de tablas.
⬥ Objetivo: enseñar sintaxis de consultas simples y complejas.
2. Sintaxis de selección e inserción
⬥ SELECT
- SELECT [ALL|DISTINCT] columnas FROM tabla [WHERE condiciones] [ORDER BY ...]
- Uso de operadores lógicos: AND, OR, NOT.
⬥ INSERT
- INSERT INTO tabla (columnas) VALUES (valores);
- Importancia del uso correcto de comillas y mayúsculas/minúsculas.
⬥ Consultas sencillas
- Uso de SELECT, WHERE, IN, LIKE, IS NULL, etc.
⬥ Ordenar datos
- ORDER BY columna [ASC|DESC]
3. Consultas de resumen
⬥ Funciones agregadas: COUNT(), SUM(), AVG(), MIN(), MAX()
4. Consultas multitabla
- Uso de varias tablas en una consulta.
- Necesidad de relaciones entre claves primarias y foráneas.
- Alias de tablas: para simplificar y acortar consultas.
- Consultas con JOIN implícito (FROM tabla1, tabla2 WHERE ...).
⬥ Operaciones entre tablas
- UNION, INTERSECT, MINUS
- Requisitos: misma cantidad y tipo de columnas.
5. Subconsultas
⬥ Una SELECT dentro de otra.
⬥ Uso para obtener datos intermedios.
6. Condiciones en subconsultas
⬥ Comparación: =, >, <, <>, >=, <=
⬥ Conjunto: IN
⬥ Existencia: EXISTS, NOT EXISTS
⬥ Comparación cuantificada: ANY, ALL
⬥ Subconsultas anidadas
7. Agrupación
⬥ GROUP BY: agrupa filas por columnas.
⬥ HAVING: filtra los grupos.
8. Vistas
⬥ Tabla virtual que almacena una consulta.
⬥ CREATE VIEW, SELECT FROM vista, DROP VIEW
⬥ Vistas de metadatos: DBA_VIEWS, USER_VIEWS
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
¿QUÉ ES UNA CONSULTA?:
Es una orden SQL, en concreto la sentencia SELECT, a la que podemos añadir una serie de condiciones para obtener información guardada dentro de las TABLAS.
SINTAXIS:
SELECT [ALL | DISTINCT] [*] [columna1], [columnaN] FROM [tabla1], [tablaN] WHERE [condición1] [AND | OR | NOT] [condiciónN] [AND | OR | NOT] ORDER BY [columna1] [DESC | ASC], [columnaN] [DESC | ASC]
BASE DE DATOS USADA EN LOS EJEMPLOS A CONTINUACIÓN:


EXPLICACIÓN SOBRE SELECT y FROM:
Estos 2 comandos son OBLIGATORIOS en toda consulta, y establecen la sintaxis básica. Le viene a pedir a la base de datos, el "QUÉ SE SELECCIONA" de "DONDE", sin esas dos partes, no puede haber consulta.
EXPLICACIÓN SOBRE ALL:
Esto va por defecto en todas las consultas, mientras no se indique lo contrario, por detrás, la consulta opera sobre TODO el contenido.No hace falta poner ALL en ninguna consulta.
EXTRAER TABLAS COMO SE MUESTRAN EN LA IMAGEN SUPERIOR:
SELECT * FROM empleados (Consulta que selecciona el contenido de toda una tabla dada para visualizarlo)
SELECT * FROM portatiles (Consulta que selecciona el contenido de toda una tabla dada para visualizarlo)
USO DE SELECT DE FORMA SELECTIVA DE COLUMNAS:
SELECT [columna/s] FROM [tabla/s]
--------------------------------------------------
SELECT COD_PC, marca FROM portatiles
Solo mostrará, de la TABLA portatiles, los atributos (columnas) dadas, en este caso COD_PC y MARCA.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE DISTINCT (ver solo EMPLEADOS cuya CIUDAD NO sea NULA (tienen ciudad asignada):
SELECT DISTINCT Ciudad FROM empleados
Solo mostrará las Ciudades distintas que hay, en este caso 3
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DEL CONDICIONAL WHERE (EMPLEADOS cuya CIUDAD sea MADRID):
SELECT * FROM empleados WHERE ciudad = 'madrid';
En este caso solo muestra los 2 que son DISTINTOS por tener como Ciudad Madrid
USO DEL CONDICIONAL WHERE + AND:
SELECT * FROM portatiles WHERE marca = 'lenovo' AND operativo = 'NO';
Concatena condicionantes, los portátiles tienen que ser marca Lenovo y NO estar operativos
USO DEL CONDICIONAL WHERE + OR (EMPLEADOS cuya CIUDAD sea MADRID):
SELECT * FROM portatiles WHERE marca = 'lenovo' OR marca = 'HP';
Mostrará los portátiles que sean de las marcas Lenovo o HP
USO DEL CONDICIONAL WHERE + NOT (EMPLEADOS cuya CIUDAD sea MADRID):
SELECT * FROM portatiles WHERE NOT marca = 'lenovo';
Que muestre todos aquellos que no sean de la marca Lenovo, es decir, los HP
USO DEL CONDICIONAL WHERE + NULL (ver solo EMPLEADOS cuya CIUDAD sea NULA (sin ciudad):
SELECT * FROM empleados WHERE ciudad IS NULL
En este caso no muestra nada, porque todos tienen ciudad asignada
USO DEL CONDICIONAL WHERE + NOT NULL (ver solo EMPLEADOS cuya CIUDAD NO sea NULA (tienen ciudad asignada):
SELECT * FROM empleados WHERE ciudad IS NOT NULL
En este caso muestra a los 4 empleados, porque todos tienen ciudad
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE ORDER BY + ASC:
SELECT * FROM portatiles ORDER BY fecha ASC;
Lista los portátiles ordenados por fecha ASCENDENTE (del 20/03/25 al 24/07/25)
USO DE ORDER BY + DESC:
SELECT * FROM portatiles ORDER BY fecha DESC;
Lista los portátiles ordenados por fecha DESCENDIENTE (del 24/07/25 al 20/03/25)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE COUNT (columna) devuelve el número de registros que contiene la tabla, SIN CONTAR aquellos NULOS:
SELECT COUNT (*) AS total_empleados FROM empleados;
Nos devolverá la suma de todos los EMPLEADOS, que son en este caso 4.
El AS es un operador que se usa para dar un alias a una columna o expresión, en este caso, total_empleados para el conteo que se pide.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE SUM (columna) suma los valores de la columna (ejemplo EXTERNO):
SELECT SUM (salario) AS total_salarios FROM empleados;
Con esto se obtiene la suma de los valores contenidos en la columna dada. En este caso sumaría los salarios de todos los empleados.
El AS es un operador que se usa para dar un alias a una columna o expresión, en este caso, total_salarios para la suma que se pide.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE AVG (columna) obtiene la media de los valores de la columna (ejemplo EXTERNO):
SELECT AVG (salario) AS media_salarios FROM empleados;
Obtenemos la media de los valores contenidos en la columna, en este caso los salarios de los empleados.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE MIN (columna) muestra el mínimo del conjunto de valores de la columna (ejemplo EXTERNO):
SELECT MIN (salario) AS minimo_salario FROM empleados;
Obtenemos el valor mínimo de los valores contenidos en la columna, en este caso los salarios de los empleados.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE MAX (columna) muestra el máximo del conjunto de valores de la columna (ejemplo EXTERNO):
SELECT MAX (salario) AS maximo_salario FROM empleados;
Obtenemos el valor máximo de los valores contenidos en la columna, en este caso los salarios de los empleados.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE AS PARA CREAR ALIAS BÁSICO (ejemplo EXTERNO):
SELECT nombre AS empleado,
salario AS sueldo
FROM empleados;
En el ejemplo anterior, se crea el ALIAS empleado para la columna nombre, y el ALIAS sueldo para la columna salario. A partir de que ejecutemos estas líneas y se creen dichos ALIAS, el programa interpretará los ALIAS creados como si se trataran de las columnas linkeadas.
USO DE AS PARA CREAR ALIAS para EXPRESIONES CALCULADAS (ejemplo EXTERNO - NO LO ENTIENDO):
SELECT nombre,
salario * 1.16 AS salario_con_iva,
COUNT(*) OVER () AS total_registros
FROM empleados;
▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂
CONSULTAS SOBRE MÁS DE UNA TABLA:
- Se pueden unir tantas tablas como se quiera.
- En la cláusula SELECT se pueden poner columnas de todas las tablas.
- Se debe identificar cada atributo con la tabla a la que corresponde.
- IMPORTANTE: En la cláusula WHERE, siempre hay que especificar la unión entre las claves primarias y ajenas. Si no se producirá un error típico que es un PRODUCTO CARTESIANO con resultados que NO son los que queremos.
- IMPORTANTE: Siempre que haya en la consulta 2 o más tablas, se recomienda el uso de ALIAS.
EJEMPLO PRÁCTICO
Diagrama E/R:
Una persona puede comprar 1 o varios artículos, y un artículo puede ser comprado por 1 o varias personas.

MODELO RACIONAL PASO A TABLAS:
PERSONAS (DNI, Nombre, Apellidos, Poblacion, Edad, Peso, Fecha_nacim)
ARTICULOS (COD_ART, Nombre, Precio, Poblacion, Peso, Color)
PER_ART (DNI, COD_ART) <----------(Tabla nueva. Los datos de esta tabla nos dirán qué personas compraron qué artículos)
NOTA: Hacer la unión en la consulta uniendo las claves PRIMARIAS con las AJENAS.
ENUNCIADO:
Se quiere obtener el DNI y NOMBRE_PERSONA de las PERSONAS y el COD_ART y el NOMBRE_ART de los ARTICULOS que hayan sido comprado por alguna persona.
🔰 CONSULTA con ALIAS:
SELECT PER.DNI, PER.Nombre, ART.COD_ART, ART.Nombre FROM PERSONAS PER, ARTICULOS ART, PER_ART PA WHERE PER.DNI = PA.DNI AND PA.COD_ART = ART.COD_ART;
🔰 EXPLICACIÓN DE CONSULTA con ALIAS:
SELECT PER.DNI, PER.Nombre, ART.COD_ART, ART.Nombre (Se indica las columnas que se coger, con unos alias que las asocian a sus tablas)
FROM PERSONAS PER, ARTICULOS ART, PER_ART PA (En esta línea se nombran las tablas y se definen los alias, en el segundo objeto)
WHERE PER.DNI = PA.DNI (Se linkea con = que, el DNI de la tabla PERSONAS es el mismo que el de PER_ART)
AND PA.COD_ART = ART.COD_ART; (Se linkea el COD_ART de ARTICULOS con el de la tabla PER_ART)
❌CONSULTA sin ALIAS:
SELECT PERSONAS.DNI, PERSONAS.Nombre, ARTICULOS.COD_ART, ARTICULOS.Nombre
FROM PERSONAS, ARTICULOS, PER_ART
WHERE PERSONAS.DNI = PER_ART.DNI
AND PER_ART.COD_ART = ARTICULOS.COD_ART;
▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂ NO ENTRA EN EL EXAMEN LA ZONA MARCADA ▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂
USO DE UNION:
UNION combina los resultados de dos consultas y elimina automáticamente cualquier duplicado. Es útil cuando quieres ver todos los empleados de dos departamentos diferentes sin repetir registros.
- Genera un nuevo conjunto de datos COMBINANDO los resultados de 2 CONSULTAS.
- Requiere que los atributos aparezcan en la misma posición de las consultas.
- Requiere que haya el mismo número de atributos.
- Requiere que todos los campos correspondientes sean del mismo tipo de datos.
- Por defecto, elimina los registros que se repiten. Si no quisiéramos que se eliminasen, debemos utilizar el comando UNION ALL.
SELECT nombre, departamento
FROM empleados
WHERE departamento = 'IT' <-----(Atención a que no hay ";" porque no termina toda la consulta)
UNION
SELECT nombre, departamento
FROM empleados
WHERE departamento = 'Desarrollo';
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE INTERSEC (INTERSECCIÓN):
Produce un nuevo resultado que contiene los elementos comunes de las dos consultas.
INTERSECT muestra solo los registros que aparecen en ambas consultas. Es útil cuando quieres encontrar empleados que cumplan dos condiciones simultáneamente.
SELECT nombre, departamento
FROM empleados
WHERE departamento = 'IT' <-----(Atención a que no hay ";" porque no termina toda la consulta)
INTERSECT
SELECT nombre, departamento
FROM empleados
WHERE departamento = 'Desarrollo';
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE MUNUS o EXCEPT, depende del sistema (DIFERENCIA):
Produce un nuevo conjunto que consiste en eliminar de la primera consulta los elementos que aparecen en la segunda consulta.
MINUS (o EXCEPT en otros sistemas) muestra los registros que están en la primera consulta pero no en la segunda. Es útil cuando quieres ver qué empleados están en un departamento pero no en otro.
SELECT nombre, departamento
FROM empleados
WHERE departamento = 'IT' <-----(Atención a que no hay ";" porque no termina toda la consulta)
MINUS
SELECT nombre, departamento
FROM empleados
WHERE departamento = 'Desarrollo';
▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂▂
USO DE SUBCONSULTAS:
Ejemplo práctico. Si queremos obtener los datos de los empleados que tengan el mismo oficio que PEPE LECHES, pero no sabemos su oficio. Solo funciona si la subconsulta devuelve 1 único resultado o valor).
SELECT * FROM empleados
WHERE oficio = (SELECT oficio FROM empleados WHERE nombre = 'Pepe' AND apellido = 'Leches');
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE SUBCONSULTAS con IN (DENTRO DE):
IN permite buscar un valor en una lista de opciones. Es como hacer múltiples comparaciones OR, pero más limpio y fácil de mantener.
SELECT nombre, departamento
FROM empleados
WHERE departamento IN ('IT', 'Desarrollo', 'RRHH');
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE SUBCONSULTAS con EXISTS:
EXISTS verifica si existe al menos un registro que cumpla la condición. Es más eficiente que IN cuando trabajas con subconsultas, ya que se detiene al encontrar el primer registro.
SELECT nombre, departamento
FROM empleados emp
WHERE EXISTS (SELECT 1 FROM proyectos pro WHERE pro.id_empleado = emp.id AND pro.estado = 'activo');
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE SUBCONSULTAS con NOT EXISTS:
NOT EXISTS es lo opuesto a EXISTS. Encuentra registros que NO tienen una relación con la subconsulta. En este caso del ejemplo, es especialmente útil para encontrar empleados sin proyectos activos.
SELECT nombre, departamento
FROM empleados emp
WHERE NOT EXISTS (SELECT 1 FROM proyectos pro WHERE pro.id_empleado = emp.id AND pro.estado = 'activo');
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE SUBCONSULTAS con ANY:
ANY encuentra registros que cumplen la condición con al menos uno de los valores de la subconsulta. En este caso, muestra empleados que ganan más que algún empleado del departamento de IT.
SELECT nombre, salario
FROM empleados
WHERE salario > ANY ( SELECT salario FROM empleados WHERE departamento = 'IT' );
OTROS CÁLCULOS con distintos OPERADORES:
= (Igual a)
> (Mayor que)
>= (Mayor o igual que)
< (Menor que)
>= (Menor o igual que)
!= (Distinto a)
<> (Distinto a)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE SUBCONSULTAS con ALL:
ALL encuentra registros que cumplen la condición con todos los valores de la subconsulta. En este caso, muestra empleados que ganan más que todos los empleados de IT.
SELECT nombre, salario
FROM empleados
WHERE salario > ALL ( SELECT salario FROM empleados WHERE departamento = 'IT' );
OTROS CÁLCULOS con distintos OPERADORES:
= (Igual a)
> (Mayor que)
>= (Mayor o igual que)
< (Menor que)
>= (Menor o igual que)
!= (Distinto a)
<> (Distinto a)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE SUBCONSULTAS "ANIDADAS":
Esta consulta anida primero encuentra el departamento de ANA, luego calcula el promedio de ese departamento, y finalmente muestra los empleados que ganan más que ese promedio.
NOTA: En el EXAMEN como mucho se piden 2 subconsultas.
SELECT nombre, salario
FROM empleados e
WHERE salario > (
SELECT AVG (salario)
FROM empleados
WHERE departamento = (
SELECT departamento
FROM empleados
WHERE nombre = 'Ana'
)
);
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE AGRUPACIÓN con GROUP BY:
GROUP BY agrupa los registros por departamento y calcula estadísticas para cada grupo. Es como hacer un resumen por categorías.
SELECT departamento,
COUNT (*) AS cantidad_empleados,
AVG (salario) AS salario_promedio
FROM empleados
GROUP BY departamento;
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE AGRUPACIÓN con HAVING:
HAVING filtra los grupos DESPUÉS de aplicar GROUP BY. Es como aplicar un filtro a los resultados agrupados, no a los registros individuales.
Hay más formas de usar HAVING pero no se usan tanto y NO entran en el EXAMEN.
SELECT departamento,
COUNT (*) AS cantidad_empleados,
AVG (salario) AS salario_promedio
FROM empleados
GROUP BY departamento
HAVING AVG (salario) > 50000;
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE CREATE (OR REPLACE) VIEW (VISTAS):
Esta vista crea una "ventana" a los empleados del departamento IT. El OR REPLACE permite actualizar la vista si ya existe.
CREATE OR REPLACE VIEW empleados_departamento AS
SELECT nombre, departamento, salario
FROM empleados
WHERE departamento= 'IT';
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
USO DE GRANT para otorgar PERMISOS:
GRANT permite controlar quién puede acceder y modificar las vistas. Es fundamental para la seguridad de la base de datos.
-- Otorgar permisos a un usuario
GRANT SELECT ON empleados_departamento TO usuario1;
GRANT CREATE VIEW TO usuario1;
-- Otorgar permisos a un rol
GRANT SELECT ON estadisticas_empleados TO rol_consultas;
GRANT EXECUTE ON empleados_proyectos TO rol_consultas;
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VISTAS:
--Ver vistas que se han creado usando tablas de METADATOS
SELECT * FROM DBA_VIEWS;
o
SELECT * FROM USER_VIEWS;
-- Borrar una vista
DROP VIEW [nombre_vista]
SQL_consultas
☑️ BASES DE DATOS TEMA 6 - OPTIMIZACIÓN DE CONSULTAS (ÍNDICES)
CREACIÓN DE ÍNDICES:
Un ÍNDICE es una estructura de datos que MEJORA la VELOCIDAD de las operaciones, permitiendo un rápido acceso a los registros de una TABLA.
- Al crear una TABLA, automáticamente se crea un ÍNDICE asociado a la CLAVE PRIMARIA que se haya definido (por lo que las búsquedas a través de la CLAVE PRIMARIA serán siempre MÁS RÁPIDAS).
- NO se puede crear un ÍNDICE para TODAS las columnas (requeriría una clave interna que asocie el registro con ese índice, consumiendo tiempo de procesamiento).
- Si se crea un índice sobre 1 SOLA COLUMNA, se llama ÍNDICE MONOCAMPO.
- Si se crea un índice sobre VARIAS COLUMNAS, se llama ÍNDICE MULTICAMPO.
📋 CREAR ÍNDICES:
UNIQUE indica que el valor de las comunas indexadas debe ser único.
CREATE UNIQUE INDEX [nombre_indice]
ON [tabla1] (columna1, comulna2);
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
📋 EJEMPLO DE ÍNDICE MONOCAMPO:
Definición: Un índice creado sobre una sola columna de una tabla.
Propósito: Mejorar el acceso rápido a registros cuando se busca por ese campo específico.
Ejemplo: Crear un índice en la columna nombre de la tabla empleados .
CREATE INDEX idx_empleado_nombre
ON empleados (nombre);
📋 EJEMPLO DE ÍNDICE ÚNICO:
Definición: Garantiza que no haya valores duplicados en la columna o conjunto de columnas indexadas.
Propósito: Asegurar integridad de datos y mejorar el rendimiento en búsquedas exactas.
Ejemplo: Un índice único en la columna dni de la tabla empleados.
CREATE UNIQUE INDEX idx_empleado_dni
ON empleados (dni);
📋 EJEMPLO DE ÍNDICE MULTICAMPO:
Definición: Un índice creado sobre múltiples columnas de una tabla.
Propósito: Mejorar búsquedas que involucran varias columnas y permitir recuperación ordenada por las columnas indexadas.
Ejemplo: Crear un índice en las columnas nombre y apellido de la tabla empleados.
CREATE INDEX idx_empleado_nombre_apellido
ON empleados (nombre, apellido);
☑️ COMPROBACIÓN DEL ÍNDICE:
SELECT INDEX_NAME, TABLE_NAME FROM USER_INDEXES;
🗑️ BORRAR UN ÍNDICE:
DROP INDEX [nombre_indice]
-------------------------------------------------------------------------------- EJEMPLO -----------------------------------------------------------------------------
CREAR TABLA TRABAJADORES PARA EJEMPLO:
CREATE TABLE Trabajadores
(
DNI_Trab VARCHAR2 (10) PRIMARY KEY,
Nombre_Trab VARCHAR2 (20),
Apellidos_Trab VARCHAR2 (30),
Edad_Trab NUMBER,
Poblacion VARCHAR2 (40),
Sueldo_Trab NUMBER
);
INTRODUCIR VALORES DE 3 TRABAJADORES EN LA TABLA DE EJEMPLO:
INSERT INTO Trabajadores VALUES ('83838383G','Julia','Jimenez',40,'Avila',30000);
INSERT INTO Trabajadores VALUES ('12121212D','Berto','Romero',45,'Barcelona',40000);
INSERT INTO Trabajadores VALUES ('53535353F','Eva','Bolaños',36,'Madrid',40000);
Ya con esto creado, podemos hacer pruebas ------------------------- v v v v v v v v -------------------------
CREAR ÍNDICE MONOCAMPO:
CREATE INDEX Index_Nom_Trab ON Trabajadores (Nombre_Trab);
☑️ COMPROBACIÓN:
SELECT INDEX_NAME, TABLE_NAME FROM USER_INDEXES;


BORAR EL ÍNDICE:
DROP INDEX Index_Nom_Trab;
--------------------------------------------------
CREAR ÍNDICE MULTICAMPO:
pueda
CREATE INDEX Index_Nom_Edad ON Trabajadores (Nombre_Trab, Edad_Trab);
BORAR EL ÍNDICE:
DROP INDEX Index_Nom_Edad;
--------------------------------------------------
CREAR ÍNDICE ÚNICO:
Este índice lo que hace es que no se pueda introducir TRABAJADORES con la misma EDAD. Solo un trabajador por edad diferente.
CREATE UNIQUE INDEX Index_Edad ON Trabajadores (Edad_Trab);
Como ya hay un trabajador con 40 años (Julia), si después de crear este índice queremos introducir otro trabajador con esas edad, tirará error.
INSERT INTO Trabajadores VALUES ('123456789PF','Lucas','Sanchez',40,'Madrid',30000);
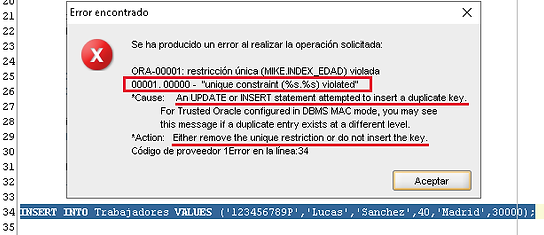
MENSAJE DE ERROR:
"Restricción única (%s.%s) violada"
Una sentencia UPDATE o INSERT intentó insertar una clave DUPLICADA.
Elimina la RESTRICCIÓN ÚNICA o no insertes la clave.
BORAR EL ÍNDICE:
DROP INDEX Index_Edad;
---------------------------------------------------------------------------- FIN DE EJEMPLO --------------------------------------------------------------------------
📊 PLAN DE EJECUCIÓN DE SENTENCIAS:
El Plan de Ejecución de una Sentencia SQL es la forma en la que Oracle ejecuta INTERNAMENTE esa sentencia. Ayuda a ANALIZAR el coste en TIEMPO y RECURSOS (uso de CPU y memoria) que va a requerir la ejecución de esa sentencia. Interesa que el VALOR del coste sea LO MENOR POSIBLE.
Con tablas pequeñas con pocos registros NO SE NOTARÁ LA DIFERENCIA, ya que apenas sería de unos microsegundos, pero si fuera una base de datos extensa con megabytes o terabytes de información, estas optimizaciones son muy importantes.
En el siguientes ejemplo utilizaremos el Plan de Ejecución de Sentencias para ver la diferencia de rendimiento entre operar SIN ÍNDICES y CON ÍNDICES.
CÓMO EJECUTARLO:
Mediante el botón de la imagen o con [F6] después de una c

VER DIFERENCIA CON EJEMPLO:
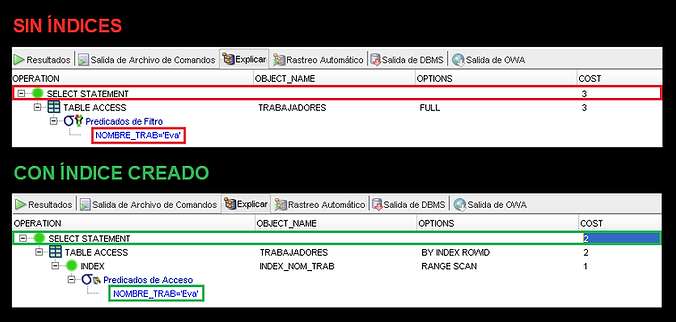
Realizamos una consulta en la tabla Trabajadores SIN ÍNDICES buscando un trabajador por nombre:
SELECT * FROM Trabajadores WHERE Nombre_Trab = 'Eva';
[📊] Pulsamos [F6] y vemos que el COSTO tiene un valor de 3.
Ahora creamos un ÍNDICE en la columna nombre:
CREATE INDEX Index_Nom_Trab ON Trabajadores (Nombre_Trab);
Se comprueba que el ÍNDICE ha sido creado correctamente:
SELECT INDEX_NAME, TABLE_NAME FROM USER_INDEXES;
Repetimos la CONSULTA anterior:
SELECT * FROM Trabajadores WHERE Nombre_Trab = 'Eva';
[📊] Pulsamos [F6] y vemos que el COSTO tiene un valor de 2, por lo que, al ser un número inferior, se traduce en mayor velocidad de operación. Si hubiéramos obtenido un COSTE de 1, sería incluso más RÁPIDO.
T6
📙 BASES DE DATOS TEMA 7 - CONSTRUCCIÓN DE GUIONES (LENGUAJE PL/SQL)
📋 RESUMEN DEL TEMA:
1. Introducción
⬥ PL/SQL: Lenguaje procedimental de Oracle para automatizar tareas en bases de datos.
⬥ Permite: variables, estructuras de control, procedimientos, funciones, excepciones, etc.
⬥ Unidad básica: bloque PL/SQL (DECLARE, BEGIN, EXCEPTION, END).
2. Estructura del bloque PL/SQL
⬥ DECLARE: declaración de variables (opcional).
⬥ BEGIN: inicio del bloque de instrucciones.
⬥ EXCEPTION: manejo de errores (opcional).
⬥ END; cierra el bloque
3. Comentarios
⬥ Una línea: -- Comentario
⬥ Varias líneas: /* Comentario */
4. Variables
⬥ Tipos:
NUMBER, VARCHAR2, CHAR, DATE
Declaración: v_edad NUMBER := 36;
⬥ Concatenación:
Se usa || o & para unir textos y variables.
⬥ %TYPE y %ROWTYPE:
- %TYPE: hereda tipo de un campo de una tabla.
- %ROWTYPE: hereda todos los campos de una fila.
⬥ SQL%ROWCOUNT:
SQL%ROWCOUNT devuelve el número de filas afectadas por INSERT, UPDATE o DELETE.
5. Entrada de datos
Se usa &IMPUT para pedir datos al usuario en tiempo de ejecución.
6. Operadores
⬥ Matemáticos: +, -, *, /, **
⬥ Comparación: =, <, >, <=, >=, <>, !=
⬥ Lógicos: AND, OR, NOT
⬥ Otros: IN, BETWEEN, IS NULL, LIKE, MOD
7. Estructuras de control
⬥ IF
Simple (IF), doble (ELSE) y múltiple (ELSIF).
⬥ CASE
Evaluación múltiple similar a switch.
⬥ LOOP
Bucle indefinido, requiere EXIT para finalizar.
⬥ WHILE
Ejecuta mientras se cumpla la condición.
⬥ FOR
Bucle con contador: FOR i IN 1..10 LOOP
8. Procedimientos y funciones
⬥ Procedimientos:
- Estructura modular sin valor de retorno.
- CREATE OR REPLACE PROCEDURE nombre (...) IS BEGIN ... END;
⬥ Funciones:
- Devuelven un valor con RETURN.
- Se pueden usar dentro de otras funciones/procedimientos.
9. Excepciones
⬥ Manejo de errores con EXCEPTION.
⬥ Tipos:
- NO_DATA_FOUND
- TOO_MANY_ROWS
- WHEN OTHERS
⬥ Uso de RAISE_APPLICATION_ERROR para mensajes personalizados.
VIDEO DE EJERCICIOS DE EJEMPLO:
----------------------------------------------------------------------------------------------------------------------------------------------------------
CONTEXTO:
El lenguaje de comandos SQ no es suficiente para un entorno empresarial en el que hay que crear scripts automáticos que tengan que ejecutar conjuntos de sentencias.
Para ello surge un LENGUAJE basado en SQL, el lenguaje PL/SQL, considerado un lenguaje POO (Programación Orientada a OBJETOS).
Este incorpora todas las características de los lenguajes de 3ª GENERACIÓN:
- Manejo de variables
- Estructura modular (procedimientos y funciones)
- Estructuras de control (bifurcaciones, bucles, etc)
- Control de excepciones
- Disparadores (triggers)
- Otros
VENTAJAS DEL PL/SQL:
PL/SQL sirve para automatizar tareas REPETITIVAS y que son PROPENSAS A ERRORES, como por ejemplo realizar cálculos PRECISOS y RÁPIDOS.
Si por ejemplo queremos sacar una suma de dos parámetros, pongamos, que de una la tabla "EMPLEADOS", queremos sumar el "Salario" y el "Complemento_de_puesto" de cada empleado, podemos hacerlo manualmente en papel, y es factible hacerlo así con 3 o 4 empleados, pero ¿y si tenemos una lista de 300? hacerlo manualmente podría llevar mucho tiempo y podríamos cometer errores en el proceso. Sin embargo, con PL/SQL podemos automatizar este cálculo en unos minutos y ejecutar la orden en segundos, obteniendo un OUTPUT con los resultados PERFECTOS.
¿CUÁNDO SERÍA ÚTIL ESTO? (en el caso del ejemplo)
- Cuando hubiera que calcular salarios de MUCHOS empleados
- SI necesitas guardas los resultados
- Necesitas generar reportes AUTOMÁTICOS
- Necesitas validar que los salarios sean CORRECTOS
- Necesitas que el proceso sea REPETIBLE periódicamente (por ejemplo cada mes)
VER UN EJEMPLO PRÁCTICO DEL CASO DESCRITO AQUÍ
BLOQUE PL/SQL:
Los programas creados a partir de lenguaje PL/SQL se pueden ALMACENAR en la base de datos quedando disponibles para su ejecución por los usuarios. LA UNIDAD DE TRABAJO ES EL BLOQUE.
Es la estructura de los PROGRAMAS PL/SQL. Tiene 3 apartados donde se especifica el código:
- Apartado de DECLARACIONES: Es [OPCIONAL]. Es donde vamos a declarar las VARIABLES y CONSTANTES.
Palabra clave: DECLARE
- Apartado de INSTRUCCIONES: Precedido por la la cláusula: BEGIN Terminado por la cláusula: END
- Apartado de TRATAMIENTO DE EXCEPCIONES: Es [OPCIONAL]. Precedido por la cláusula: EXCEPTION
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
SINTAXIS DE BLOQUE PL/SQL:
[DECLARE]
[declaraciones]
BEGIN
[órdenes]
[EXCEPTION]
[gestión_de_excepciones]
END;
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
EJECUCIÓN DE UN BLOQUE PL/SQL:
Este lenguaje NO está diseñado para interactuar con el USUARIO. Tiene una PESTAÑA por donde nos mostrará la información que se llama SALIDA DE DBMS, que hay que seleccionar después de ejecutar un BLOQUE, para ver el OUTPUT.
Lo siguiente es clicar en la pestaña de 📮 SALIDA DE DBMS, y 💬 ACTIVAR la SALIDA de DBMS. Es necesario para que se visualice el OUTPUT generado por los bloques PL/SQL, en este caso set serveroutput on, que indica que la SALIDA DBMS queda activada.

Una vez hecho lo anterior, se puede generar mensajes dentro de esa pestaña, a través de la línea de comandos de arriba:
DBMS_OUTPUT.PUT_LINE [mensaje_de_salida];
Siempre dentro de un "BEGIN" y un "END;" para marcar inicio y final del código. Se ejecuta igual que las líneas SQL, con selección de texto y al botón de "► Ejecutar Sentencia" [F9] , o con [F5] para ejecutar todas las líneas. Especial atención a las ";" que cierran línea de código.
------------------------------------------------------------------------------ EJEMPLOS -------------------------------------------------------------------------------
BLOQUE PL/SQL BÁSICO (SIN variables):
Mostrar un texto como output.
BEGIN
DBM_OUTPUT.PUT_LINE ('Esto es una prueba');
DBM_OUTPUT.PUT_LINE ('Esto también');
END;
BLOQUE PL/SQL con COMENTARIOS (SIN variables):
Mostrar comentarios con el output. Los comentarios no tienen ninguna función.
BEGIN
-- Esto es un comentario corto
DBM_OUTPUT.PUT_LINE ('Esto es una prueba');
/* Esto es un comentario largo que ocupa más de una línea de la caja de texto del programa */
END;
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
DECLARAR E INICIAR VARIABLES:
Las variables almacenan datos que pueden variar a lo largo de la ejecución del código.
Se DECLARAN ANTES del "BEGIN", en la sección "DECLARE". El formato es el siguiente:
DECLARE
[nombre_variable] [tipo_de_dato] := [valor];
NOTA: para una lectura más rápida del código, se recomienda empezar las variables con "V_". Ejemplo de variable:
v_variable_salario
TIPOS DE DATOS:
NUMBER
CHAR
VARCHAR2
DATE
EJEMPLOS DE DECLARACIÓN de VARIABLES con los diferentes TIPOS DE DATOS:
DECLARE
v_importe NUMBER(3) ; (sin inicializar. define número de 3 cifras)
v_contador NUMBER(2) := 0; (inicializado con un valor NEUTRO. define número de 2 cifras)
v_salario_base NUMBER := 30000; (define un número concreto. no define límite de cifras)
v_tipo CHAR := 'A'; (define un caracter concreto. sin límite. usar comillas. mejor usar VARCHAR2)
v_nombre_trabajador VARCHAR2(10) NOT NULL := ' '; (inicializado con valor neutro. límite de 10 caracteres. usar comillas)
v_nombre_trabajador VARCHAR2 (10) := 'Juan'; (inicializado con un valor. límite de 10 caracteres. usar comillas)
v_fecha_nacimiento DATE := '1999-12-30'; (el formato ANSI 'YYYY-MM-DD' es más seguro para fechas. usar comillas)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
EJEMPLO DE SUMA DE DOS VARIABLES:
DECLARE
v_salario_base NUMBER := 30000;
v_bonificacion NUMBER := 5000;
v_total NUMBER;
BEGIN
v_total := v_salario_base + v_bonificacion;
DBMS_OUTPUT.PUT_LINE ('Salario total: ' || total);
END;
OUTPUT:
Salario total: 35000
Lo que ha hecho el programa es definir que la variable v_salario_base equivale a 30.000€, la variable v_bonificacion equivale a 5.000€, y que la variable v_total es un número, que posteriormente se establece como el resultado de sumar las variables v_salario_base y v_bonificacion, sacándolo así por el OUTPUT (30.000 + 5.000 = 35.000).
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
EJEMPLO DE MOSTRAR VARIABLE DEFINIDA:
DECLARE
v_mensaje_random VARCHAR2 (30) := 'Hola esto es una prueba';
BEGIN
DBMS_OUTPUT.PUT_LINE (v_mensaje_random);
END;
OUTPUT:
Hola esto es una prueba
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
EJEMPLO DE MOSTRAR VARIABLES DEFINIDAS, UNIDAS con PIPES || , añadidas también con [Alt Gr] + [1]:
DECLARE
v_nombre VARCHAR2 (10) := 'Pepe';
v_edad NUMBER (2) := '32';
BEGIN
DBMS_OUTPUT.PUT_LINE ('El trabajador:' || v_nombre || 'tiene' || v_edad || 'años');
END;
OUTPUT:
El trabajador Pepe tiene 32 años
----------------------------------------------------------------------------- FIN EJEMPLOS ---------------------------------------------------------------------------
DATOS ESPECIALES
%TYPE:
Declara una variable del mismo tipo que un atributo de una tabla ya creada.
- No hace falta conocer el TIPO de atributo de la tabla
- Si se cambia el TIPO de atributo de la tabla, no supone un problema. De no hacerlo así, habría que ir buscando todos los códigos
desarrollados y cambiarlos en todos.
SINTAXIS:
[nombre_variable]
[nombre_tabla] . [nombre_atributo] %TYPE
%ROWTYPE:
Declara una variable del mismo tipo que una fila de atributos de una tabla ya creada, es decir, un registro. Lo usaremos cuando veamos cursores.
SINTAXIS:
[nombre_variable] [nombre_tabla] %ROWTYPE
Para visualizar el dato de un atributo una vez cargado en la variable hay que poner en el comando DBMS_OUTPUT.PUT_LINE:
[nombre_variable] . [nombre_atributo]
Cuando hacemos una consulta y queremos guardar información de uno o varios atributos en variable tenemos que usar la siguiente ESTRUCTURA:
SELECT atributo1, atributo2 INTO v_variable1, v_variable2 FROM tabla;
SQL%ROWCOUNT:
Devuelve el número de filas recuperadas hasta el momento por la sentencia INSERT, DELETE o UPDATE. Se pone justo DESPUÉS de una sentencia INSERT, DELETE o UPDATE. Para guardar el valor que obtiene hay que asignarlo a una variable.
EJEMPLO:
DECLARE
v_edad NUMBER :=0;
BEGIN
Sentencia INSERT, DELETE o UPDATE;
v_edad NUMBER := SQL%ROWCOUNT;
DBMS_OUTPUT.PUT_LINE (v_edad);
END;
EXPLICACIÓN:


OPERADORES y EXPRESIONES:
Se pueden realizar operaciones y cálculos matemáticos con los datos guardados en las variables, si programamos en PL/SQL debidamente.
Con los siguientes OPERADORES es posible realizar cálculos complejos.
** (potencia)
* (multiplicación)
/ (división)
+ (suma)
- (resta)
|| (concatenación)
= (comparación: igual que)
> (comparación: mayor que)
< (comparación: menor que)
>= (comparación: mayor o igual que)
<= (comparación: menor o igual que)
<> (comparación: distinto que)
!= (comparación: distinto que)
IS NULL (comprueba si un valor es nulo)
LIKE (busca patrones)
BETWEEN (busca entre un rango de valores)
IN (busca coincidencia exacta entre valores)
NOT (niega una condición)
AND (combina condiciones que deben ser verdaderas)
OR (al menos una condición debe ser verdadera)
CÁLCULO EJEMPLO (HACER UNA MEDIA):
Calcular mediante PL/SQL la media de 4 valores, como por ejemplo, la que sería la nota media de 4 exámenes, que se obtendría sumando las 4 notas y dividiéndolas entre 4.
DECLARE
v_nota_1 NUMBER(2,1) := 7.2; <-------(aquí (2,1) define que el primer número puede tener 2 dígitos, y que después de la coma, 1 dígito)
v_nota_2 NUMBER(2,1) := 5.5; <-------(el valor de NUMBER no necesita comillas, y la coma se tiene que definir con un punto)
v_nota_3 NUMBER(2,1) := 6.0;
v_nota_4 NUMBER(2,1) := 8.0;
v_MEDIA NUMBER := 0;
BEGIN
v_MEDIA := (v_nota_1 + v_nota_2 + v_nota_3 + v_nota_4)/4;
DBMS_OUTPUT.PUT_LINE ('La media de mis notas es: ' || v_MEDIA);
END;
OUTPUT:
La media de mis notas es: 6.7
INTRODUCCIÓN DE VALORES POR EL USUARIO EN UN BLOQUE PL/SQL (&):
El símbolo & en PL/SQL tiene dos funciones principales:
1- Como operador de CONCATENACIÓN en cadenas de texto. ES PREFERIBLE USAR "||" PARA CONCATENACIÓN POR VARIOS MOTIVOS.
2- Como indicador de variable de SUSTITUCIÓN (IMPUT introducido por el usuario).
1) EJEMPLO de OPERADOR de CONCATENACIÓN:
DECLARE
v_nombre VARCHAR2(20) : = 'Juan';
v_mensaje VARCHAR2(30);
BEGIN
v_mensaje := v_nombre & ' Pérez'; <-- (Concatena 'Juan' con 'Pérez'. para esto es mejor no usar "&")
v_mensaje := v_nombre || ' Pérez'; <-- (También concatena 'Juan' con 'Pérez'. éste método es preferible)
DBMS_OUTPUT.PUT_LINE (v_mensaje); <-- Muestran: Juan Pérez
END;
OUTPUT:
Juan Pérez
2) EJEMPLO de VARIABLE DE SUSTITUCIÓN:
DECLARE
v_nombre VARCHAR2(20);
BEGIN
v_nombre := '&IMPUT'; <-- El sistema pedirá el valor al usuario al ejecutar
DBMS_OUTPUT.PUT_LINE ('Bienvenido ' || v_nombre);
END;
OUTPUT:
Bienvenido [IMPUT]
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ESTRUCTURA DE CONTROL (IF, ELSE, ELSIF,CASE, LOOP, WHILE, FOR):
En un nuevo nivel de complejidad de programación PL/SQL tenemos las ITERACIONES, que son ejecuciones de sentencias que se van a ejecutar reiteradamente hasta que haya una condición que se termine de cumplir o no se cumpla que hará que s termine la ejecución.
Hay de varios tipos.
SENTENCIAS IF:
ALTERNATIVA SIMPLE.
Si la condición se cumple se ejecutan las instrucciones después del THEN.
IF [condición] THEN
[instrucciones1];
END IF;
ALTERNATIVA DOBLE.
Si la condición se cumple se ejecutan las instrucciones después del THEN, si no, se ejecutarán las instrucciones después del ELSE.
IF [condición] THEN
[instrucciones1];
ELSE
[instrucciones2];
END IF;
ALTERNATIVA MÚLTIPLE CON ELSEIF.
Se van analizando las condiciones desde el principio hasta encontrar alguna condición que se cumpla en cuyo caso ejecutará las intrucciones después del THEN. La cláusula ELSE es opcional, esta se ejecutará si no encuentra una condición válida.
IF [condición] THEN
[instrucciones1];
ELSEIF [condición] THEN
[instrucciones2];
ELSEIF [condición] THEN
[instrucciones3];
. . .
[ELSE
[otras_instrucciones; ]
END IF;
SENTENCIAS CASE:
Evalúa cada condición hasta encontrar alguna que se cumpla. Si encuentra alguna, ejecutará las instrucciones después de la cláusula THEN. La cláusula ELSE es opcional, si está en el código, se ejecutará si no encuentre una condición válida.
CASE
WHEN [condición] THEN
[instrucciones1];
WHEN [condición] THEN
[instrucciones2];
WHEN [condición] THEN
[instrucciones1];
. . .
[ELSE
otras_instrucciones; ]
END CASE;
SENTENCIAS LOOP:
Es un BUCLE que se repetirá indefinidamente hasta que encuentre una instrucción EXIT sin condición o hasta que se cumpla la condición asociada a la cláusula EXIT WHEN.
LOOP
[instrucciones];
EXIT [WHEN [condición] ];
[instrucciones];
END LOOP;
SENTENCIAS WHILE:
Se evalúa la condición y si se cumple se ejecutarán las instrucciones del bucle. El bucle se seguirá ejecutando mientras se cumpla la condición.
WHILE [condición] LOOP
[instrucciones];
END LOOP;
SENTENCIAS FOR:
Bucle que gestiona un número de repeticiones que conocemos. El índice del bucle no hay que declararlo, el bucle FOR lo hace internamente.
FOR [índice] IN [REVERSE] [valor_inicial] . . . [valor_final] LOOP
[instrucciones];
END LOOP;
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
PROCEDIMIENTOS:
PL/SQL dispone de una serie de estructuras que permiten almacenar códigos. Son bloques PL/SQL que tienen un nombre y pueden recibir y devolver valores (parámetros). Quedan guardados en la base de datos y se pueden ejecutar en cualquier momento.
Se puede temer PROCEDIMIENTOS y FUNCIONES que llamen a otros procedimientos funciones dentro de su código.
SINTAXIS GENERAL DE PROCEDIMIENTOS:
CREATE [OR REPLACE] PROCEDURE [nombre_procedimiento] [(parámetros)]
IS/AS
[declaraciones]
BEGIN
[órdenes]
[EXCEPTION]
[gestión_de_excepciones]
END;
NOTA: [(parámetros)] en la lista de parámetros opcionales se puede pasar al procedimiento una serie de valores, con este formato:
(p_param1 TIPO1, p_param2 TIPO2, . . . )
NOTA: En los parámetros al definir el TIPO, NO se define el tamaño. Es decir:
❌ p_edad NUMBER(2)
✔️ p_edad NUMBER
LLAMAR AL PROCEDIMIENTO PARA SU EJECUCIÓN:
BEGIN
[procedimiento] [(valor_param1, valor_param2, . . . )];
END;
EJEMPLO SENCILLO:
Procedimiento sencillo de ejemplo que sólo mostrará un mensaje.
CREATE OR REPLACE PROCEDURE PRINT_MESSAGE
AS
BEGIN
DBMS_OUTPUT.PUT_LINE ('Esto es una prueba')
END;
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
FUNCIONES:
PL/SQL dispone de una serie de estructuras que permiten almacenar códigos. Son bloques PL/SQL que tienen un nombre y pueden recibir y devolver valores (parámetros). Quedan guardados en la base de datos y se pueden ejecutar en cualquier momento.
Se puede temer PROCEDIMIENTOS y FUNCIONES que llamen a otros procedimientos funciones dentro de su código.
SINTAXIS GENERAL DE FUNCIONES:
CREATE [OR REPLACE] FUNCTION [procedimiento] [(parámetros)]
RETURN [tipo_de_valor_devuelto]
IS/AS
[declaraciones]
BEGIN
[órdenes]
RETURN [expresión]
[EXCEPTION]
[gestión_de_excepciones]
END;
NOTA: [(parámetros)] en la lista de parámetros opcionales se puede pasar al procedimiento una serie de valores, con este formato:(p_param1 TIPO1, p_param2 TIPO2, . . . )
NOTA: En los parámetros al definir el TIPO, NO se define el tamaño. Es decir:
❌ p_edad NUMBER(2)
✔️ p_edad NUMBER
- OPCIÓN 1 (guardando el resultado en una variable):
DECLARE
v_resultado [tipo_dato];
BEGIN
v_resultado := [nombre_función] [(valor_param1,
valor_param2)];
END;
- OPCIÓN 2 (usando directamente el resultado, en este caso lo visualizamos):
BEGIN
DBMS_OUTPUT.PUT_LINE (nombre_función [(valor_param1,
valor_param2)];
END;
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
FUNCIONES:
Las excepciones sirven para tratar errores en tiempo de ejecución, así como errores y situaciones definidas por el usuario.
Cuando se produce un error en PL/SQL, levanta una EXCEPCIÓN y pasa el control a la sección EXCEPTION, donde buscará un manejador WHEN para la excepción o uno genérico WHEN OTHERS y dará por finalizada la ejecución del bloque actual.
El formato de la sección EXCEPTION es:
[EXCEPTION]
WHEN [nombre_excepción1] THEN
[instrucciones];
WHEN [nombre_excepción2] THEN
[instrucciones];
. . .
WHEN OTHERS THEN
[instrucciones];
END;
FUNCIONES IMPLÍCITAS:
Son aquellas excepciones definidas por Oracle, a saber:
WHEN NO_DATA_FOUND (NO SE HA ENCONTRADO EL DATO)
Se ejecuta cuando la consulta ha dado ERROR de que no se ha encontrado el dato que se ejecutaba.
WHEN TOO_MANY_ROWS (DEMASIADOS VALORES)
Se ejecuta cuando la consulta ha devuelto más de un dato para la búsqueda que se ha realizado.
WHEN xxxxxx ( ? )
ERROR definido por el usuario. Lo veremos más adelante.
WHEN OTHERS THEN ( ? )
Se debe poner al final. Se ejecuta cuando no es ninguno de los ERRORES anteriores. Oracle sólo sabe que se ha producido un ERROR, pero no sabe de qué tipo o por qué ha sucedido.
👁️ VISUALIZAR EL ERROR:
- Mediante el comando: DBMS_OUTPUT.PUT_LINE (mensaje_de_error) <-- que ya conocemos
- Mediante una pantalla de error con el comando: RAISE_APPLICATION_ERROR (-20001, 'mensaje_de_error');
Este tipo de mensajes generados por el USUARIO comienzan en el código de error -20001 y se va asignando descendentemente si hay otros códigos de error, es decir, el siguiente sería -20002, -20003 y así sucesivamente.
T7
suma_PL/SQL
T8
🔒 BASES DE DATOS TEMA 8 - GESTIÓN SEGURIDAD DE DATOS (EXP-IMP)
POSIBLES INCIDENTES CON LA INFORMACIÓN:
☠️ Ataques informáticos (exfiltración, encriptación y/o eliminación de información)
💾 Fallos de Software
⚙️ Problemas de Hardware
⚡ Fallos eléctricos (apagones, sobrecargas...)
🔥 Desastres naturales, incendios, inundaciones...
✋ Errores humanos
Primero hay que PREVENIR estos escenarios e implementar todas las medidas posibles que lo consigan totalmente o en mayor medida.
Y en caso de que el sistema se vea comprometido, disponer de mecanismos de recuperación.
SEGURIDAD INFORMÁTICA:
Oracle cuenta con una utilidad que se llama RMAN (Recovery MANager) que se usa para hacer COPIAS DE SEGURIDAD. Tiene la ventaja de OPTIMIZAR el espacio y RENDIMIENTO en el disco cuando hace los backup.
ELEMENTOS A PROTEGER:
- El Sistema: Es imprescindible usar medios que controle el ACCESO y USO que hacen los usuarios de la BBDD.
- Los Datos: Es también imprescindible tener una serie de COPIAS DE RESPALDO para recuperar la información en caso de necesidad.
- La Infraestructura: Es recomendable, si es preciso, tener sistemas duplicados (servidores, sistemas de refrigeración, de corriente...) para,
que si cae uno de ellos, automáticamente pueda activarse otro y no cortarse el servicio.
TIPOS DE COPIAS DE SEGURIDAD:
Oracle ofrece unas herramientas y mecanismos que desde el ADMINISTRADOR DE BASE DE DATOS pueden realizar lo siguiente:
✅ Mantener los datos DISPONIBLES el CUALQUIER MOMENTO
🛡️ PROTEGER la base de datos ante POSIBLES FALLOS
💾 COPIAS DE SEGURIDAD
Y se pueden hacer 2 CLASIFICACIONES según:
- Si la BASE DE DATOS está PARADA o ACTIVADA:
- ❄️ COPIA EN FRÍO: Se paran los servicios y la propia base de datos para evitar que los usuarios accedan a ella.
- 🔥 COPIA EN CALIENTE: NO se paran ni los servicios ni la base de datos, pudiendo incluso acceder los usuarios.
Hay sistemas críticos que NO SE PUEDEN PARAR.
- Según el TIPO DE INFORMACIÓN almacenada:
- 🧱 FÍSICA o en CRUDO: Almacena los archivos físicos que contienen la base de datos. Guarda archivos .dbf y
archivos de control de parámetros (configuraciones). Son MUY RÁPIDAS y pueden ser realizadas
en FRÍO y en CALIENTE.
- 🧠 LÓGICA: Se extraen los datos de las TABLAS exportándolas a ficheros. Se llaman exportaciones de datos y
suelen ser mas LENTAS.
- Según el TIPO DE COPIA:
- 🟦 COMPLETA: Se almacena TODA la información de la base de datos.
- ⏫ INCREMENTAL: Se guarda SÓLO la INFO que se MODIFICÓ o es NUEVA desde la ÚLTIMA COPIA de seguridad.
Las copias de seguridad deberían hacerse con regularidad almacenándose en diversos medios de soporte y que no estén en la misma ubicación.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
TRANSFERENCIA DE DATOS ENTRE SISTEMAS GESTORES:
Las OPIAS DE SEGURIDAD LÓGICAS se pueden cargar en otros sistemas similares mediante ficheros de exportación.
COMANDOS:
Se ejecutan en la consola de ejecución de comandos de Windows (CMD).
C:\[carpeta]>EXP [usuario]/[contraseña] full=yes (exportar todas las TABLAS del usuario + contraseña, en la carpeta de consola)
C:\[carpeta]>EXP [usuario]/[contraseña] full=yes help=yes (exportar todas las TABLAS del usuario + contraseña, en la carpeta de consola, con ayuda)
C:\[carpeta]>IMP [usuario]/[contraseña] file=expdat.dmp full=yes (importar un archivo dmp a un usuario de la base de datos, en la carpeta de consola)
EXPORTACIÓN (EXP):
Todas las exportaciones se guardan en un archivo llamado EXPDAT.DMP. Para crear COPIAS ADICIONALES, le cambiamos el nombre al archivo citado para que cree OTRO. En el proceso de exportación, hay que ir contestando preguntas (mediante [intro] o la tecla [y]).
COMPROBAR la creación de la COPIA en la consola CDM:
dir
C:\[carpeta] dir
IMPORTACIÓN (IMP):
Para exportar una copia (archivo .DMP) a un usuario de la base de datos. Para verificar que la importación se realizó correctamente, debemos abrir SQL DEVELOPER y comprobarlo en el desplegable del usuario que recibió la importación, en la categoría TABLAS.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
💼 BASES DE DATOS TEMA 9 - BASES DE DATOS DISTRIBUIDAS
BASES DE DATOS DISTRIBUIDAS:
Se llama así a cuando TENEMOS UNA BASE DE DATOS CUYA INFORMACIÓN SE ENCUENTRA REPARTIDA en 2 o más SERVIDORES. Estos servidores estarán intercomunicados a través de una RED DE ENLACES que será transparente para el administrador de redes (sin la necesidad de saber COMO están conectados esos servidores).
Por ejemplo, podría pasar que en una Base de Datos, la tabla CLIENTES se encuentre en un servidor en Londres, y la tabla PEDIDOS se encuentre en otro servidor en FRANKFURT.
✔️ VENTAJAS:
- Mayor FIABILIDAD y TOLERANCIA A FALLOS.
Aunque algún servidor se caiga, es posible mantener que el resto del sistema siga funcionando, aunque sea en parte.
- Mayor RAPIDEZ de ACCESO A DATOS y mayor ALMACENAMIENTO.
Al haber más máquina se incrementa la CAPACIDAD DE CÁLCULO, rapidez de búsqueda y mayor espacio (al haber más máquinas) para almacenar la información.
- ESCALABILIDAD.
Repartiendo la base de datos en diferentes sitios se puede INCREMENTAR los RECURSOS de cada sitio según la DEMANDA.
- FLEXIBILIDAD de ACCESO.
Los usuarios pueden acceder a más ubicaciones con lo que se evitan saturaciones o accesos concurrentes al mismo sitio.
¿QUÉ SE NECESITA?
- Un SGBD con capacidad para gestionar BBDD DISTRIBUIDAS.
- BBDD LOCALES en cada uno de los distintos SERVIDORES.
- Una RED de comunicaciones fluida entre los distintos sitios.
- ENLACES entre las BBDD LOCALES.
- Un DICCIONARIO de DATOS que englobe e identifique en qué BBDD LOCAL está cada uno de los datos.
TÉCNICAS DE FRAGMENTACIÓN:
Fragmentar consiste en TROCEAR una Base de Datos. Se puede fragmentar:
🗃️ A NIVEL DE LA BASE DE DATOS: Cada tabla o tablas se ubican en diversos servidores.
📅 A NIVEL DE TABLA: Se divide la tabla y se guardan en diversos servidores, con 3 POSIBILIDADES (Horizontal, Vertical o Mixta).
- Horizontal: Se dividen los REGISTROS.
Por ejemplo, de una tabla Jugadores, los registros del jugador 1 al 100 están en un servidor, y del 101 al 200 en otro servidor.
Recordemos que un registro son todos los datos de una línea, que abarca todos los atributos.
- Vertical: Se divide la tabla por ATRIBUTOS.
Por ejemplo, de una tabla Jugadores, se dividirán los datos de estos por columnas/atributos en los distintos servidores,
estableciendo una CLAVE PRIMARIA como nexo común entre los 2 o más servidores.
- Mixta: Mezcla de las técnicas anteriores.
EJEMPLO GRÁFICO:
⚠️NOTA:
Cada servidor SOLO TIENE UNA COPIA de la información que almacena. Es decir, que LA FRAGMENTACIÓN NO DUPLICA REGISTROS NI TABLAS. Para ese otro cometido, se debe tener copias de seguridad de las Bases de Datos Locales para no perder la información ante un posible problema de pérdida de datos.
ESQUEMA DE REPLICACIÓN DE DATOS:
En una Base de Datos distribuida NO HAY DUPLICIDAD de datos (redundancia). Para incrementar el rendimiento en los accesos y consultas de una BBDD se puede usar un ESQUEMA de replicación de datos que DUPLICA tanto la ESTRUCTURA como los DATOS.
¿QUÉ SE NECESITA?
- UN NODO MAESTRO: Este recibirá todas las MODIFICACIONES y ACTUALIZACIONES sobre los datos.
- NODOS ESCLAVOS: Reciben las ACTUALIZACIONES y CAMBIOS del NODO MAESTRO. Cuando haya modificaciones se hará un proceso de importación desde el NODO MAESTRO para tener una copia actualizada de los cambios producidos.
En otras palabras, hay servidor central (NODO MAESTRO) donde se centraliza la información, en el que se cargan y almacenan todos los cambios, y los NODOS ESCLAVOS se conectan al MAESTRO para replicar en LOCAL el contenido que les envía el NODO MAESTRO.

T9
❓ BASES DE DATOS - PREGUNTAS TIPO TEST (click y mantener para ver acierto o fallo)
1. ¿Cuál es la sentencia básica para realizar una consulta en SQL?
SHOW
SELECT
EXTRACT
GET
2. ¿Qué hace la cláusula DISTINCT en una consulta SQL?
Devuelve valores únicos, sin diplicados
Agrupa los datos duplicados
Elimina columnas vacías
Ordena los resultados alfabéticamente
3. ¿Cuál es el propósito de la cláusula WHERE en una consulta?
Especificar qué columnas mostrar
Crear una nueva tabla
Ordenar resultados
Filtrar filas según una condición
4. ¿Qué operador se usa para buscar valores dentro de un conjunto específico?
LIKE
IN
ANY
BETWEEN
5. ¿Cuál de estas consultas muestra todos los registros de la tabla personas, cuyo nombre comience por la letra "M"?
SELECT * FROM personas WHERE nombre = 'M';
SELECT * FROM personas WHERE nombre LIKE 'M';
SELECT * FROM personas WHERE nombre LIKE 'M%';
SELECT * FROM personas WHERE nombre = 'M%';
6. ¿Qué palabra clave se utiliza para ordenar los resultados en orden descendente?
ORDER DESC
DESC
DOWN
ORDER DOWN
7. ¿Cuál de las siguientes funciones sirve para contar cuántos registros hay en una tabla?
COUNT()
LENGHT()
SUM()
ROWCOUNT()
8. ¿Qué sucede si no se especifica correctamente la relación entre las tablas en una consulta con varias tablas?
Se agrupan todos los resultados
La consulta se cancela
Se produce un producto cartesiano
Se borran las tablas relacionadas
9. ¿Cuál es el uso principal del operador BETWEEN en una cláusula WHERE?
Seleccionar valores dentro de un rango
Comparar texto
Contar valores
Excluir datos duplicados
10. ¿Qué hace la sentencia UNION entre dos consultas SQL?
Elimina consultas vacías
Agrupa los resultados por clave primaria
Devuelve la intersección de los resultados
Combina resultados de dos consultas eliminando duplicados
11. ¿Cuál de las siguientes estructuras de control ejecuta un bloque de instrucciones mientras una condición se cumpla?
LOOP
WHILE
FOR
IF
12. ¿Qué operador se usa para concatenar textos en PL/SQL?
CONCAT
&
||
+
13. ¿Cuál es el uso principal de %TYPE?
Declarar variables con el mismo tipo que un atributo de tabla
Declarar variables con distinto tipo de atributo
Repetir valores
Ejecutar funciones
14. ¿Con qué código se muestran mensajes por la salida estándar - OUTPUT?
DBMS_OUTPUT.PUT_SHOW
DBMS_OUTPUT.PUT_LINE
DBMS_OUTPUT.PUT_TEXT
DBMS_OUTPUT.PUT_NEW
15. ¿Qué palabra clave se utiliza para indicar el inicio de un bloque de código ejecutable en PL/SQL?
EXECUTE
START
DECLARE
BEGIN
16. ¿Cuál es el propósito de la cláusula EXCEPTION?
Declarar variables
Insertar datos
Manejar errores en tiempo de ejecución
Eliminar registros
17. ¿Qué operador permite saber cuántas filas ha afectado una operación DML?
%ROW
%ROWCOUNT
SQL%ROW
SQL%ROWCOUNT
18. ¿Qué tipo de comentario se usa para varias líneas?
// //
--
/* */
** **
19. ¿Qué tipo de variable almacena todos los campos de una fila de una tabla?
%ROWTYPE
%ARRAY
%ROW
%TYPE
20. ¿Qué estructura ejecuta un bloque un número definido de veces?
WHILE
FOR
LOOP
CASE
21. ¿Qué cláusula se utiliza para comprobar múltiples condiciones en cascada?
CASE
IF
LOOP
COMPARE
22. ¿Cómo se llama la salida donde se muestran los mensajes generados por DBMS_OUTPUT.PUT_LINE?
Output window
Output console
DBMS window
Salida de DBMS
23. ¿Qué instrucción se debe ejecutar para visualizar los mensajes en la consola?
SET SERVEROUTPUT ON
SET OUTPUT.PUT ON
SET CONSOLEOUTPUT ON
SET DBMSOUTPUT ON
24. En un Esquema de Replicación de datos ¿cómo se llama al servidor que recibe, registra y distribuye las actualizaciones y modificaciones?
Nodo Principal
Nodo Matriz
Nodo Maestro
Nodo Central
25. Completa los campos vacíos de los siguientes PASOS A TABLAS:

26. Completa los campos vacíos de las siguientes relaciones JERARJQUICAS:
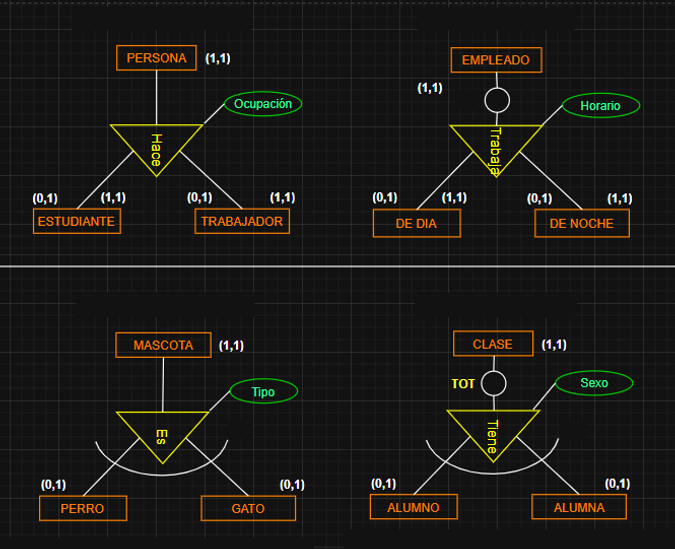
27. ¿Cómo se declara una VARIABLE en un bloque PL/SQL después del comando DECLARE?
v_nombre VARCHAR2(20) : Juan;
v_nombre VARCHAR2(20) : 'Juan';
v_nombre VARCHAR2(20) := Juan;
v_nombre VARCHAR2(20) := 'Juan';
28. ¿Qué FUNCIÓN definida por Oracle define que "no se ha encontrado el dato que se ejecutaba"?
NO_DATA_MATCH
NO_DATA_FOUND
NO_EJECUTION_MATCH
NO_EJECUTION_FOUND
29. ¿Y cual define que una "consulta ha devuelto más de un dato para la búsqueda que se ha realizado"?
TOO_MANY_DATA
TOO_MANY_ERRORS
TOO_MANY_ROWS
TOO_MANY_ROWCOUNT
30. ¿Qué es correcto sobre la sentencia LOOP?
El bucle se seguirá ejecutando mientras se cumpla la condición
El bucle se ejecutará siempre
El bucle se ejecutará hasta donde se le indique
No crea ningún bucle
31. El contenido de un fichero binario:
Son algunas de estas extensiones: inf, conf, sql, html
Debe ser interpretado mediante una aplicación específica
También se pueden llamar ficheros planos o ASCII
Se puede abrir con un editor de textos y es legible por el ser humano
32. ¿?
S
H
P
D
test
📝 BASES DE DATOS - POSIBLES EJERCICIOS PRÁCTICOS DE EXAMEN (3 de 6)
TIPO 1 - Diagrama Entidad / Relación:
Dado un enunciado obtener el esquema conceptual.
TIPO 2 - Paso a Tablas:
Dado un diagrama E/R realizar el Paso a Tablas.
TIPO 3 - Crear una TABLA con restricciones:
CREATE TABLE.
TIPO 4 - Modificar aspectos de una TABLA existente:
ALTER TABLE.
TIPO 5 - Consultas / Subconsultas:
Realizar Consultas y/o Subconsultas a una BBDD.
TIPO 6 - Bloque PL/SQL:
Crear un código usando un bloque modular PL/SQL.
ejerciciosEXAM
bottom of page