
REPOSITORIO
GENERAL DE IA

⚙️ MACHINE LEARNING
🐶 Cats/Dogs Detect (Kaggle)
❎ Proyecto 1X2 (Google Colab)
📝 APUNTES
💬 NATURAL LANGUAJE
🗒️ Probando NotebookLM
😃 Hugging Chat
🟢 ChatGPT
👨💻 Advanced Prompt Engineering
👁️ COMPUTER VISION
🖼️ Probando Teachable Machine
🈸 Probando TensorFlow
👨 Face Recognition (Google Colab)
LEYENDA DE COLORES
▉ BLANCO Archivos / Encabezados / Palabras destacadas / Output resultante de un comando
▉ [PARÉNTESIS] [Parámetros a introducir en una línea de comandos]
▉ GRIS Introducciones / Aclaraciones / Texto explicativo
▉ VERDE Sintaxis / Comandos / Código genérico
▉ VERDE PÁLIDO Prompts / Python / SVD
▉ AZUL Rutas / Directorios / "Windows"
▉ AZUL CLARO URLs / IPs / Markdown
▉ ROSA Destacar parámetros en una línea de comandos
▉ ROJO Comandos de privilegios / stderr / Atención
▉ NARANJA Valor variable / Usuarios / Grupos / Contraseñas / TCP / "Linux"
▉ AMARILLO Puertos / UDP / JavaScript / php / Bases de datos
🤖 ¿QUÉ ES LA IA?
LOS SISTEMAS INFORMÁTICOS SE CLASIFICAN EN DOS CATEGORÍAS:
🔹 Sistemas TRADICIONALES: Aquellos sistemas programados por humanos con instrucciones específicas que hacen aquello para lo que han sido programados y como han sido programados. Su funcionamiento es predecible. En esta categoría se incluye a todo programa informático tradicional.
🔹 Sistemas INTELIGENTES: Se denominan así a aquellos sistemas que funcionan de forma autónoma después de un entrenamiento previo, para una o unas funciones concretas. Su funcionamiento es, a diferencia de los sistemas tradicionales, mayormente impredecible. Aquí empieza a caminar lo que conocemos como "Inteligencia Artificial".
INTELIGENCIA ARTIFICIAL
Es el término que hace referencia a una serie de tecnologías que utilizan extensas bases de datos para automatizar procesos de análisis y predicción, que responden de forma autónoma a las cuestiones y problemas que se les plantean. A base a los datos utilizados, contribuyendo a la toma de decisiones, reducen la intervención humana y los errores derivados de la misma.
A menudo se utilizan expresiones como "inteligencia" y "aprendizaje" de forma incorrecta. Estas tecnologías no aprenden en el sentido estricto de la palabra, ni adquieren inteligencia propiamente dicha, entendida como la capacidad de razonar, entender y adquirir conocimiento, aunque son capaces de simular estas capacidades humanas, en algunos casos de forma indistinguible.
En tareas concretas, estas tecnologías son capaces de superar al humano en velocidad y precisión, si bien la eficacia de estas capacidades dependerá siempre de la calidad y cantidad de los datos que se utilicen para "entrenar" al modelo de IA que los aplica.
APLICACIONES ACTUALES DE LA IA:
🤖▸ ASISTENTES VIRTUALES: Siri, Alexa, Google Assistant...
📊▸ RECOMENDADORES DE CONTENIDO: En plataformas como Netflix, Amazon, Spotify...
💊▸ MEDICINA: Diagnóstico predictivo, análisis de imágenes médicas, desarrollo de tratamientos personalizados...
🎓▸ EDUCACIÓN: Plataformas de aprendizaje adaptativo, tutores virtuales, análisis de desempeño estudiantil...
¿DE QUÉ ES CAPAZ LA INTELIGENCIA ARTIFICIAL?
Por poner solo algunos ejemplos:
- Asistentes virtuales que pueden interactuar con el usuario, responder preguntas y solucionar problemas
- Modelos predictivos capaces de mejorar la precisión en la predicción del clima
- Reconocimiento de objetos y personas en imágenes y video, de utilidad en CCTV de vigilancia y seguridad
- Sistemas de recomendación personalizado en plataformas online
- Sistemas de conducción autónoma
- Diagnóstico precoz de enfermedades
- Análisis de imágenes médicas como radiografías, con la detección temprana de tumores y enfermedades
- Predicción de trayectorias de asteroides y cometas
- Descubrimiento de exoplanetas en estrellas lejanas
- Robots y maquinaria industrial capaz de automatizar y realizar tareas complejas con precisión
- Y un largo ETC
ESQUEMA BÁSICO DEL FUNCIONAMIENTO DE UN SISTEMA DE INTELIGENCIA ARTIFICIAL:

MODELOS DE DESARROLLO:
🏷️ APRENDIZAJE SUPERVISADO:
Se basa en un conjunto de DATOS ETIQUETADOS para enseñar al modelo a realizar una tarea específica.
EJEMPLOS: Clasificación de imágenes, reconocimiento facial, reconocimiento por voz...
❌ APRENDIZAJE NO SUPERVISADO:
El modelo busca patrones en datos NO ETIQUETADOS.
EJEMPLOS: Marketing personalizado, redes sociales, buscadores de contenido...
💰 APRENDIZAJE POR REFUERZO:
El modelo aprende a tomar decisiones mediante RECOMPENSA o CASTIGO.
EJEMPLOS: AlphaGo o AlphaZero, que son programas que aprenden a jugara videojuegos y mejoran con el tiempo.
🧠APRENDIZAJE PROFUNDO (DEEP LEARNING):
Utiliza REDES NEURONALES PROFUNDAS con múltiples capas para aprender representaciones de datos COMPLEJAS.
EJEMPLOS: NLPs como ChatGPT, DALL-e, Copilot, Gemini, DeepFake...
PROCEDIMIENTO BÁSICO DE ENTRENAMIENTO DE UN MODELO DE INTELIGENCIA ARTIFICIAL - MACHINE LEARNING:
Este proceso de entrenamiento de un modelo de IA se conoce como "Machine Learning" (aprendizaje automático) y se puede resumir en 4 fases:
► FASE 1 - OBTENER UNA BASE DE DATOS
Primero se necesita una base de datos como materia prima. Los datos pueden estar en una base de datos estructurada, si estos se componen de valores (palabras y números), y no estructurada, si los datos se almacenan en "lenguaje natural", en formato de imagen, de audio o de vídeo.
► FASE 2 - ADECUAR LA BASE DE DATOS
El posterior estudio y refinado de esos datos (ETL - Extraction, Transform and Load) adecuándolos a las necesidades del modelo.
► FASE 3 - ENTRENAMIENTO DEL MODELO (Machine Learning)
La creación de un modelo de aprendizaje con los datos resultantes. Consta básicamente de una serie de instrucciones de programación (generalmente en lenguajes como Python), que darían forma al algoritmo matemático que trabajará los datos. Los algoritmos buscarán e identificarán patrones y compararán los resultados mediante fórmulas matemáticas que calculan métricas de error o precisión, mostrando como resultado final aquellos valores de mayor probabilidad.El modelo de aprendizaje se puede plantear de tres formas diferentes, complementarias entre si. Aprendizaje supervisado (cuando poseemos unos resultados correctos con los que comparar), aprendizaje no supervisado (cuando no se dispone de otros resultados con los que comparar) y el aprendizaje por refuerzo, que sería reafirmar o corregir al modelo en función de la precisión de sus respuestas/resultados.
► FASE 4 - AFINADO DEL MODELO (Fine-Tuning)
El reajuste del modelo y la ampliación de ese modelo de aprendizaje con información de refuerzo (fine-tuning) y la creación de redes neuronales (modelos computacionales inspirados en cómo el cerebro humano procesa la información, que están compuestos por capas de "nodos" o "neuronas" interconectados que contienen una función de activación).
► FASE 5 - DESPLIEGUE (Deployment)
Se ejecuta el modelo y se observan los resultados. Los modelos son impredecibles, no se puede conocer el alcance de su funcionamiento hasta que son ejecutados.

📚
☑️
🎯
⚙️
▶️

⇦ CICLO EN EL ENTORNO EMPRESARIAL
► FASE 1 - Entendimiento del negocio
Analizar y entender el negocio, sus características y sus necesidades específicas.
► FASE 2 - Entendimiento de los datos
Analizar y y entender los datos disponibles.
► FASE 3 - Preparación de los datos
Preparar los datos para que tengan una calidad y coherencia suficiente para el modelo.
► FASE 4 - Modelado
Entrenar el modelo con algoritmos y código, para que entienda y procese los datos.
► FASE 5 - Evaluación
Evaluar el ecosistema datos-modelo, que sea correcto y adecuado.
► FASE 6 - Despliegue
Desplegar el modelo y comprobar finalmente su funcionamiento (output).
HISTORIA DE LA IA (línea Temporal de hechos relevantes)
1764 - Se publica el Teorema de Bayes
1842 - Ada Lovelace sienta las bases del primer algoritmo
1847 - George Boole crea la Lógica Booleana
1936 - Alan Turing propone una máquina que pueda aprender
1942 - Isaac Asimov formaliza l"Las 3 Leyes de la Robótica" en su libro "Runaround"
1952 - Arthut Samuel crea los primeros programas para computadora en IBM
1956 - En la Conferencia de Dartmouth, organizada por John McCarthy, Marvin Minsky, Claude Shannon y Nathaniel Rochester, marcó el nacimiento oficial de la IA como campo de estudio. Fue en esta conferencia donde se acuñó
el término "Inteligencia Artificial"
1959 - Se crea MDALINE, la primera red neuronal artificial
1985 - Sejnowski y Rosenber crean la red neuronal NetTalk
2006 - Geoffrey Hinton inventa el término "Deep Learning"
2012 - Google crea una red neuronal no supervisada
2016 - AlphaGo vence al primer jugador humano al juego estratégico del "Go"
2016 - Se populariza el término "Machine Learning"
2018 - Se crea AlphaFold1, tecnología capaz de precedir estructuras de proteínas
2018 - OpenAI lanza ChatGPT 1. Este modelo demostró las posibilidades del aprendizaje no supervisado utilizando libros como fuente de entrenamiento
2020 - OpenAI lanza ChatGPT 3. Este modelo marcó un salto cualitativo, pudiendo redactar correos electrónicos,
artículos periodísticos, generar códigos y traducir entre idiomas
2022 - Se lanza públicamente ChatGPT 3.5, alcanzando rápidamente el millón de usuario. El lanzamiento de ChatGPT
parece marcar un punto de inflexión incluso para los escépticos, destacando así el avance notable en esta
disciplina.
2025 - Se lanza públicamente ChatGPT 5, demostrando nuevos niveles de lógica y razonamiento.
TIMELINE:
Clicar para ampliar
MÁS INFORMACIÓN:
► Actualmente la IA se puede dividir en 4 tipos:
- 🧿 Predictiva (con el objetivo de hacer predicciones en base a datos para anticipar problemas)
- 💬 Procesamiento de lenguaje natural (con el objetivo de interactuar con el usuario de diferentes maneras)
- 👁️ Visión Artificial (con el objetivo de reconocer formas, objetos y patrones en imágenes)
- 🌌 Generativa (con el objetivo de crear contenido, ya sea en formato de texto, de iagen, de audio o de vídeo)
► El acceso libre a datos, modelos y código ha fomentado una cultura de colaboración y transparencia, impulsando la innovación y rompiendo las barreras de entrada a un campo que de otra manera estaría dominado por grandes empresas con recursos exclusivos (domina el Open Source).
► El análisis de grandes volúmenes de datos, la automatización de tareas repetitivas, la personalización de la experiencia del cliente y la detección de fraudes son solo algunos ejemplos de cómo la IA se ha integrado en diversas industrias.
► Los primeros ejemplos de éxito:
- Robots industriales
- Sistemas de recomendación / content filtering
- Búsquedas web
- Speech to text (Alexa o Siri)
► El Deep Learning permite a las máquinas aprender patrones complejos a partir de grandes cantidades de datos, sin necesidad de una programación explícita.
► La IA es una disciplina que se ejerce con software. Requiere de ciertas instrucciones mediante el uso de un lenguaje de programación (Python), habiéndose convertido en el lenguaje de programación dominante en el campo de la IA, gracias a su sintaxis clara, su amplia gama de bibliotecas especializadas y su vibrante comunidad.
► El interés en la IA se disparó en 2016, habiéndose multiplicado por 10 entre ese año y la actualidad, el número de proyectos relacionados con la misma en GitHub.
► Python es un lenguaje de programación de alto nivel, interpretado y multiparadigma:
- Fácil de leer: Utiliza una sintaxis simple y similar al inglés, lo que facilita la legibilidad del código.
- Interpretado: Ejecuta el código directamente sin necesidad de compilación previa.
- Multiparadigma: Soporta programación orientada a objetos, imperativa y funcional.
- Tipado dinámico: No requiere declarar tipos de variables explícitamente.
- Gran biblioteca estándar: Ofrece una amplia gama de funciones predefinidas para diversas tareas
► Algunas herramientas online basadas en Python para aprender y trabajar Machine Learning:
- ♓ Kaggle (Plataforma en línea para aprender y practicar machine learning y análisis de datos)
- 🉑 Google Colab (Entorno de desarrollo en línea para Jupyter Notebooks)
- 💡 Jupyter (Sistema para crear y ejecutar notebooks interactivos de código)
- 🟡 CoCalc (Plataforma de desarrollo de software y ciencia de datos en la nube)
- ⚪ Saturn Cloud (Plataforma de desarrollo de software y ciencia de datos en la nube)
► Algunas librerías de código Python específicas para Machine Learning y Deep Learning:
- 🈸 TensorFlow (Framework de aprendizaje automático y redes neuronales desarrollado por Google)
- 🈴 Keras (Framework de aprendizaje profundo que se ejecuta sobre otros frameworks como TensorFlow o Theano)
- 🔥 Pytorch (Framework popular para deep learning, conocido por su flexibilidad y facilidad de uso)
- 🧪 Scikit-Learn (Biblioteca de aprendizaje automático tradicional para Python)
- 🐼 Pandas (Biblioteca para análisis de datos en Python)
- 🧮 NumPy (Base para muchas otras bibliotecas científicas de Python)
.jpg)
📑 DICCIONARIO DE TÉRMINOS, ACRÓNIMOS Y SIGLAS
BAJAR NOTA: En orden alfabético ascendente
ALGORITMO: Un algoritmo es un conjunto de instrucciones o pasos que una máquina sigue para resolver un problema o realizar una tarea. En inteligencia artificial los algoritmos son las "recetas" que permiten a los sistemas "aprender" (mediante prueba y error supervisado o refuerzo) y tomar decisiones.
ALUCINACIONES: En el contexto de la inteligencia artificial, las alucinaciones ocurren cuando un modelo, como un chatbot o un sistema de generación de texto, produce respuestas o resultados que no son correctos ni están basados en datos reales. Es decir, inventa o genera información falsa que parece creíble, pero no tiene fundamento en los datos que fue entrenado. Esto lo hace el modelo porque está obligado por definición a contestar (devolver un output).
ANOMALIAS: Son datos que se desvían significativamente del patrón o comportamiento esperado. Estos datos inusuales pueden indicar errores, fraudes, fallos del sistema u otros eventos poco comunes. Detectar anomalías es útil para identificar problemas o eventos fuera de lo normal.
API (Application Programming Interface): Es un conjunto de reglas y protocolos que permiten que diferentes programas o sistemas se comuniquen entre sí. En inteligencia artificial, las API permiten integrar modelos de IA, como servicios de procesamiento de lenguaje o reconocimiento de imágenes, en otras aplicaciones de manera sencilla.
APRENDIZAJE NO SUPERVISADO: Es un tipo de aprendizaje automático (machine learning) en el que el modelo trabaja con datos que no tienen etiquetas ni respuestas conocidas. El objetivo es descubrir patrones, relaciones o estructuras ocultas en los datos, como agrupar elementos similares (clustering) o reducir la dimensión de los datos. A diferencia del aprendizaje supervisado, no se le da al modelo ejemplos con respuestas correctas, por lo que debe aprender por sí mismo a interpretar los datos.
APRENDIZAJE POR REFUERZO: Es un tipo de aprendizaje automático (machine learning) en el que el modelo se entrena con datos etiquetados, es decir, ejemplos que ya tienen las respuestas correctas. El objetivo es que el modelo aprenda a predecir o clasificar nuevos datos basándose en esos ejemplos. Por ejemplo, si entrenas un modelo con imágenes de gatos y perros (etiquetadas como "gato" o "perro"), aprenderá a identificar si una nueva imagen es de un gato o un perro.
APRENDIZAJE SUPERVISADO: Es un tipo de aprendizaje automático (machine learning) en el que un modelo aprende a tomar decisiones mediante ensayo y error. El modelo interactúa con un entorno y recibe recompensas o penalizaciones según sus acciones. El objetivo es que el modelo maximice las recompensas a largo plazo, aprendiendo qué acciones son las mejores para alcanzar un objetivo. Es similar a cómo los humanos o animales aprenden comportamientos a través de las consecuencias de sus acciones.
ARQUITECTURA: La arquitectura en inteligencia artificial se refiere al diseño y estructuración de sistemas informáticos que permiten a las máquinas realizar tareas que normalmente requieren inteligencia humana. Es el conjunto de principios y componentes que definen cómo se organiza y funciona un sistema artificial inteligente.
ARRAY (arreglo): Es una estructura de datos más general que puede ser de una o más dimensiones. Un array unidimensional puede ser similar a un vector, pero un array también puede ser bidimensional (como una tabla o matriz) o tener más dimensiones, lo que lo hace más flexible para almacenar y manipular grandes cantidades de datos en IA.
ASSISTANT API: Es una interfaz que permite a los desarrolladores integrar y utilizar las capacidades de un asistente virtual en sus propias aplicaciones. Estas capacidades pueden incluir procesamiento de lenguaje natural, generación de respuestas, manejo de conversaciones, y otras funciones avanzadas de inteligencia artificial. A través de esta API, los desarrolladores pueden construir asistentes personalizados o mejorar la interacción con los usuarios, permitiendo que las aplicaciones respondan de forma más inteligente y automática a las necesidades de los usuarios.
ATS (Applicant Tracking System): Es un software que ayuda a gestionar el proceso de contratación automatizando tareas como la recolección, clasificación y evaluación de candidatos. Utiliza algoritmos y técnicas de IA para filtrar currículums, identificar las mejores coincidencias con las descripciones de los trabajos y optimizar el proceso de selección. Esto agiliza la contratación y reduce la carga de trabajo para los equipos de recursos humanos.
BIAS: Un bias o sesgo es una tendencia en el modelo que provoca resultados parciales o inexactos, generalmente debido a datos de entrenamiento incompletos o no representativos, interpretaciones erróneas de patrones o influencias inconscientes de los desarrolladores. Esto puede causar que la IA discrimine o perpetúe desigualdades, por lo que es esencial identificar y mitigar sesgos para garantizar decisiones justas y precisas.
BIG DATA: Se refiere a conjuntos de datos extremadamente grandes, complejos y variados que son difíciles de procesar utilizando herramientas y métodos tradicionales. Estos datos suelen ser generados a gran velocidad y provienen de diversas fuentes, como redes sociales, dispositivos IoT, transacciones, sensores, entre otros. La clave del Big Data es la capacidad de analizar estos grandes volúmenes de datos para extraer información valiosa, patrones y tendencias que puedan ayudar en la toma de decisiones o en el desarrollo de nuevas tecnologías, como la inteligencia artificial.
BOUNDING BOX: O caja de contorno, en Computer Vision. Es una forma rectangular que encapsula o circunda objetos de interés en una imagen. Su propósito principal es definir la ubicación y tamaño de un objeto en un espacio bidimensional o tridimensional. Las bounding boxes se usan principalmente en tareas de detección de objetos, donde se identifican y clasifican objetos en imágenes y videos. Son fundamentales para localizar y analizar objetos en imágenes. Existen diferentes formas de representar las bounding boxes, como coordenadas de los vértices superiores e inferiores, o un conjunto de coordenadas junto con la anchura y altura. Son fáciles de implementar y entender, y cada vez más eficientes computacionalmente. Permiten representar objetos de diferentes formas y tamaños de manera robusta.
CLOUD COMPUTING: También conocido como computación en la nube, es un modelo de servicio que permite acceder a recursos informáticos, como almacenamiento, procesamiento y aplicaciones, a través de internet en lugar de tener que gestionarlos en servidores locales o dispositivos personales. Los usuarios pueden alquilar estos recursos de manera flexible y escalable, pagando solo por lo que necesitan y utilizando la potencia de grandes centros de datos distribuidos. Esto facilita la ejecución de proyectos que requieren mucho poder computacional, como los relacionados con inteligencia artificial o Big Data, sin necesidad de infraestructura física propia.
CNN: O Red Neuronal Convolucional, es un tipo de red neuronal diseñada para procesar imágenes y videos. Utiliza capas de convolución para detectar patrones visuales, como bordes y formas, lo que permite clasificar imágenes, reconocer objetos y realizar otras tareas de visión por computadora. Su estructura combina capas de filtros y reducción de datos, permitiéndole aprender características complejas de forma eficiente.
COMMON CRAWL: Es una gran fuente de datos web abiertos que se utiliza para entrenar modelos de lenguaje y otras aplicaciones de IA. Proporciona enormes cantidades de texto y otros contenidos extraídos de la web, lo que permite a los investigadores y desarrolladores entrenar modelos con datos reales y diversos, mejorando su rendimiento en tareas como la comprensión del lenguaje natural y la generación de texto.
COMPUTER VISION: También conocido como visión por computadora, es un campo de la inteligencia artificial que permite a las máquinas interpretar y comprender el mundo visual. Utiliza algoritmos y técnicas para que los ordenadores puedan "ver" y analizar imágenes, videos o cualquier tipo de datos visuales. Esto incluye tareas como reconocer objetos, identificar rostros, detectar movimientos o interpretar escenas. Es fundamental en aplicaciones como la conducción autónoma, el reconocimiento facial, el análisis de imágenes médicas y la realidad aumentada.
CONTEXT WINDOW: Específicamente en modelos de lenguaje como GPT, la context window se refiere a la cantidad máxima de palabras, tokens o caracteres que un modelo puede procesar y "recordar" en una sola vez. Es decir, es el tamaño del texto que el modelo puede tener en cuenta para generar una respuesta o realizar una tarea. Si el texto excede el límite de la ventana de contexto, el modelo pierde parte de la información anterior. Modelos con una mayor ventana de contexto pueden entender mejor las relaciones y patrones en textos largos.
DASHBOARD: O tablero, es una herramienta visual que muestra de manera clara y concisa datos importantes, métricas y KPIs (indicadores clave de rendimiento) en un solo lugar. Suele utilizar gráficos, tablas y otros elementos visuales para facilitar la interpretación rápida de la información. En el ámbito de la inteligencia artificial y el machine learning, los dashboards se utilizan para monitorear el rendimiento de modelos, visualizar resultados de análisis de datos y tomar decisiones basadas en los datos en tiempo real.
DATA ANALYST: O analista de datos, es un profesional que recopila, procesa y analiza datos para extraer información útil y relevante. Su trabajo consiste en interpretar los datos para ayudar a las empresas o instituciones a tomar decisiones informadas. Utilizan herramientas estadísticas, software especializado y técnicas de visualización de datos para identificar patrones, tendencias y correlaciones que puedan mejorar la eficiencia, identificar oportunidades o resolver problemas. En resumen, un data analyst transforma los datos en insights que guían decisiones estratégicas.
DATA MINING: O minería de datos, es el proceso de explorar grandes conjuntos de datos para identificar patrones, relaciones y tendencias ocultas. Utiliza técnicas estadísticas, algoritmos de machine learning y herramientas avanzadas para descubrir información útil que no es evidente a simple vista. El objetivo es extraer conocimiento valioso de los datos que puede ayudar en la toma de decisiones, como predecir comportamientos de los clientes, detectar fraudes o mejorar procesos de negocio. Es una parte clave del análisis de Big Data.
DATA SCIENCE: O ciencia de datos, es un campo interdisciplinario que combina técnicas de estadística, matemáticas, programación y análisis para extraer conocimientos y tomar decisiones basadas en datos. Los científicos de datos utilizan grandes volúmenes de datos para construir modelos predictivos, identificar patrones y obtener insights que pueden aplicarse en diversos sectores, como negocios, salud, finanzas y tecnología. La ciencia de datos incluye procesos como la recopilación de datos, limpieza, análisis, visualización y el uso de machine learning para hacer predicciones o automatizar decisiones.
DATA SPLIT: Es el proceso de dividir un conjunto de datos en tres partes: entrenamiento (para enseñar al modelo), validación (para ajustar su rendimiento) y prueba (para evaluar su precisión final). Esto ayuda a garantizar que el modelo generalice bien a datos nuevos.
DATASET: Es un conjunto de datos organizado, generalmente en forma de tablas, que se utiliza para entrenar y evaluar modelos de machine learning. Cada fila representa un ejemplo o instancia, y cada columna contiene una característica o variable de esos ejemplos.
DATASET BALANCEADO: Es aquel en el que las clases o categorías están representadas de manera equitativa. Es decir, cada clase tiene un número similar de ejemplos. Esto es importante en machine learning, ya que un dataset desequilibrado (con muchas más instancias de una clase que de otra) puede sesgar el modelo hacia la clase mayoritaria, afectando su capacidad de predecir correctamente las clases minoritarias.
DEEP LEARNING: Es una rama del machine learning que se basa en redes neuronales artificiales de muchas capas (redes neuronales profundas). Estas redes están diseñadas para aprender representaciones complejas de los datos, imitando en parte el funcionamiento del cerebro humano. Es especialmente útil para tareas como el reconocimiento de imágenes, procesamiento de lenguaje natural y análisis de grandes volúmenes de datos, donde se requiere identificar patrones complejos.
EMBEDDING: Es una representación numérica de datos, como palabras, imágenes o cualquier tipo de información, en un espacio vectorial de menor dimensión. Su objetivo es capturar las características o relaciones más importantes del dato en un formato que el modelo de IA pueda procesar de manera eficiente.
ENTRENE: En inteligencia artificial, "entrenar" se refiere al proceso de preparar y capacitar a un modelo de IA para realizar tareas específicas. Este proceso implica: Alimentar al modelo con grandes cantidades de datos etiquetados, que sirven como base de aprendizaje. Permitir que el modelo analice y procese estos datos para identificar patrones y relaciones.
Iterativamente ajustar y refinar el modelo basándose en sus errores y desempeño. El objetivo es que el modelo aprenda a tomar decisiones y hacer predicciones de manera precisa, utilizando los patrones extraídos de los datos de entrenamiento. Este proceso de aprendizaje continuo permite que la IA mejore su rendimiento con el tiempo, adaptándose a nuevas situaciones y datos.
EPOCH: Una epoch es una pasada completa a través del conjunto de datos de entrenamiento por parte del modelo. Durante una epoch, el modelo ajusta sus parámetros (pesos) a medida que aprende de los datos. Generalmente, se necesitan varias epochs para que el modelo optimice su rendimiento, ya que en cada epoch el modelo mejora basándose en el error acumulado de las iteraciones anteriores.
ESCALAR VARIABLES NUMÉRICAS: En Machine Learning, escalar las variables significa cambiar sus valores para que todas estén en un rango similar o en una misma escala. Esto sirve para evitar que algunas variables dominen sobre otras.
ETIQUETAS: Son las respuestas o categorías que se asignan a cada ejemplo en un conjunto de datos. En machine learning supervisado, las etiquetas indican el valor o clase que queremos que el modelo prediga. Por ejemplo, en un dataset de imágenes de animales, las etiquetas serían "gato", "perro", etc., y se utilizan para que el modelo aprenda a identificar correctamente los animales en nuevas imágenes.
EXPLICABILIDAD: Se refiere a la capacidad de un modelo para hacer comprensibles sus decisiones y procesos a los humanos. En modelos complejos como los de deep learning, es difícil entender cómo se toman las decisiones, por lo que la explicabilidad busca ofrecer transparencia, justificando por qué un modelo ha llegado a una conclusión. Es importante para garantizar la confianza, la ética y el uso responsable de la IA, especialmente en áreas sensibles como la salud, la justicia o las finanzas.
FINE-TUNING: Es una técnica en la que se toma un modelo de IA pre-entrenado y se ajusta (o afina) a una nueva tarea específica, entrenándolo con un conjunto de datos más pequeño y especializado. En lugar de entrenar un modelo desde cero, el fine-tuning permite aprovechar los conocimientos previos del modelo y adaptarlos a nuevas necesidades, ahorrando tiempo y recursos.
FRAMEWORK: Es un conjunto de herramientas, bibliotecas y reglas predefinidas que facilitan el desarrollo y la implementación de modelos de IA. Ayuda a los desarrolladores a crear aplicaciones más rápido, proporcionando una estructura básica sobre la cual construir, en lugar de tener que empezar desde cero. Ejemplos populares incluyen TensorFlow y PyTorch.
FORECASTING: O pronóstico, es el proceso de predecir valores futuros basándose en datos históricos. En machine learning y análisis de datos, se utilizan modelos para analizar patrones pasados y proyectar posibles resultados futuros, como ventas, demanda, clima o precios. Es común en finanzas, negocios y planificación logística, donde la capacidad de anticipar cambios es crucial para la toma de decisiones.
GARBAGE: O "basura", se refiere a datos de mala calidad, irrelevantes o incorrectos que pueden afectar negativamente el rendimiento de un modelo o análisis. El concepto se resume en la frase "garbage in, garbage out" (basura entra, basura sale), lo que significa que si los datos de entrada son malos, los resultados o predicciones también lo serán. Es fundamental trabajar con datos limpios y precisos para obtener modelos y análisis confiables.
GPU: O Unidad de Procesamiento Gráfico por sus siglas en inglés, es un tipo de procesador diseñado para manejar cálculos intensivos y en paralelo, como los que se necesitan para procesar gráficos y video. En inteligencia artificial y machine learning, las GPUs son muy útiles porque pueden acelerar significativamente el entrenamiento de modelos complejos, como redes neuronales profundas, al procesar grandes cantidades de datos de manera simultánea. Esto las hace mucho más eficientes que las CPU para ciertas tareas relacionadas con deep learning y big data.
HERRAMIENTAS DE VISUALIZACIÓN: Transforman datos en gráficos y dashboards para facilitar su análisis. Ejemplos comunes incluyen Tableau, Power BI, Matplotlib, y Google Data Studio. Estas herramientas ayudan a identificar patrones y tomar decisiones informadas rápidamente.
HIDDEN LAYERS: O capas ocultas, son capas intermedias en una red neuronal que procesan la información entre la capa de entrada y la capa de salida. Estas capas realizan cálculos complejos y transforman los datos mediante funciones activación, permitiendo al modelo aprender patrones más profundos y abstractos. En redes neuronales profundas (deep learning), suele haber muchas capas ocultas, lo que permite al modelo capturar relaciones complejas en los datos.
HUMANIZERS: Son herramientas o técnicas diseñadas para hacer que las interacciones de IA o los modelos automatizados parezcan más humanas. Su objetivo es mejorar la interacción y la experiencia del usuario haciendo que la IA sea más comprensiva, empática o adaptada al comportamiento humano. Esto puede incluir aspectos como el uso de un lenguaje más natural, emociones simuladas o respuestas adaptadas al contexto, para que las personas perciban a la IA como más cercana y "humana".
IA GENERATIVA: Es un tipo de inteligencia artificial que crea contenido nuevo, como texto, imágenes, audio o video, a partir de datos existentes. Utiliza modelos como redes generativas adversarias (GANs) o transformadores (como GPT) para generar resultados originales basados en patrones aprendidos. Es útil en áreas como la creación de arte, generación de texto automático, síntesis de imágenes, y creación de modelos 3D, entre otros.
IDE: Entorno de Desarrollo Integrado, por sus siglas en inglés. Es una aplicación de software que proporciona herramientas completas para programar y desarrollar aplicaciones. Un IDE generalmente incluye un editor de código, un depurador, y un compilador o intérprete, todo en una única interfaz. Ejemplos populares de IDEs son Visual Studio Code, PyCharm y Eclipse. Los IDEs facilitan el desarrollo al ofrecer autocompletado, resaltado de sintaxis y gestión de proyectos en un solo lugar.
ITERACIONES: En machine learning y programación se refieren a los ciclos repetitivos en los que un proceso o algoritmo se ejecuta varias veces para mejorar o refinar los resultados. En el entrenamiento de modelos, cada iteración implica actualizar los parámetros del modelo basándose en los errores anteriores, con el objetivo de minimizar el error y mejorar la precisión del modelo a lo largo del tiempo.
JUPYTER: Es una plataforma interactiva que permite crear y compartir documentos llamados notebooks, que pueden contener código ejecutable, visualizaciones, texto explicativo y ecuaciones matemáticas. Es especialmente popular en data science y machine learning porque permite realizar análisis de datos, experimentar con código y visualizar resultados en un solo entorno. Jupyter soporta varios lenguajes de programación, siendo Python el más utilizado.
KAGGLE: Es una plataforma en línea para científicos de datos y entusiastas del machine learning. Ofrece competencias donde los usuarios pueden resolver problemas reales usando datos, colaborar con otros y aprender nuevas técnicas. Kaggle también proporciona datasets públicos, notebooks interactivos, y herramientas como GPUs para entrenar modelos. Es un lugar popular para aprender, compartir proyectos, y mejorar habilidades en ciencia de datos y machine learning.
KERAS: Es una biblioteca de código abierto para construir y entrenar modelos de redes neuronales. Es fácil de usar y modular, lo que permite a los desarrolladores diseñar modelos de deep learning de manera rápida. Keras funciona como una capa de alto nivel sobre bibliotecas más potentes como TensorFlow, simplificando el proceso de crear y entrenar redes neuronales complejas. Es ideal para principiantes y expertos que buscan desarrollar modelos de machine learning con menos complejidad técnica.
LDM (Latent Diffusion Model): Es un tipo de modelo generativo basado en la técnica de difusión latente, que genera imágenes u otros tipos de datos de alta calidad a partir de ruido. Los LDMs funcionan aplicando un proceso de difusión, que comienza con datos aleatorios (ruido) y gradualmente los transforma en datos estructurados, como imágenes, a través de una serie de pasos. Se utilizan principalmente en tareas como la generación de imágenes y la síntesis de contenidos. Este enfoque permite modelos más eficientes y precisos en comparación con otras técnicas generativas.
LEARNING RATE: En la inteligencia artificial es la velocidad a la que un modelo de aprendizaje automático se adapta a los datos en cada iteración del entrenamiento. Indica el tamaño del paso que se toma para llegar a la solución óptima en un problema de optimización. Es un parámetro crucial que afecta tanto la precisión como la eficiencia del modelo. Un learning rate adecuado permite reducir el error conforme pasan las épocas hasta llegar al mínimo buscado. Se pueden utilizar técnicas como el decrecimiento del learning rate conforme disminuye la función de pérdida para lograr un ajuste óptimo. Los valores típicos suelen estar entre 0.1, 0.01 y 0.001. Una elección incorrecta puede llevar a problemas de convergencia o lentitud excesiva en el entrenamiento.
LLM (Large Languaje Model): Es un tipo de modelo de inteligencia artificial entrenado en grandes cantidades de datos textuales para comprender y generar lenguaje natural. Estos modelos, como GPT, pueden realizar tareas como traducción, resumen, generación de texto y responder preguntas. Los LLMs son capaces de aprender patrones complejos del lenguaje y generar respuestas coherentes y relevantes basadas en los datos con los que fueron entrenados. Son ampliamente utilizados en aplicaciones de chatbots, asistentes virtuales y otros sistemas de procesamiento del lenguaje natural.
MACHINE LEARNING: O aprendizaje automático, es una rama de la inteligencia artificial que permite a los sistemas aprender de los datos y mejorar su rendimiento en tareas específicas sin ser programados explícitamente para ello. Los algoritmos de machine learning identifican patrones en los datos y utilizan esos patrones para hacer predicciones o tomar decisiones. Se aplica en áreas como reconocimiento de voz, recomendación de productos, detección de fraudes y muchos más.
MARKDOWN: Ees un lenguaje de marcado ligero que permite dar formato a texto de manera sencilla utilizando una sintaxis simple. Se utiliza principalmente para crear documentos que luego se pueden convertir a HTML u otros formatos. Con Markdown, puedes agregar encabezados, listas, enlaces, imágenes, y más, sin la complejidad de lenguajes como HTML. Es muy popular en plataformas como GitHub, Jupyter notebooks, y sistemas de blogs debido a su simplicidad y facilidad de lectura.
MEMORIA RAM: O Random Access Memory, es un tipo de memoria volátil que los dispositivos utilizan para almacenar temporalmente datos y programas que están en uso activo. A diferencia del almacenamiento permanente, como un disco duro, la RAM se borra cuando el dispositivo se apaga. Es fundamental para el rendimiento de un sistema, ya que permite un acceso rápido a los datos, facilitando que los programas y el sistema operativo funcionen de manera eficiente. Cuanta más RAM tiene un dispositivo, mayor es su capacidad para manejar múltiples tareas y aplicaciones de forma simultánea.
MODELO: Es una representación matemática o computacional que se entrena con datos para realizar tareas específicas, como hacer predicciones, clasificar información o tomar decisiones. El modelo aprende patrones a partir de los datos y, una vez entrenado, puede aplicarse a nuevas entradas para generar resultados. Los modelos pueden ser de diferentes tipos, como redes neuronales, árboles de decisión o máquinas de soporte vectorial, dependiendo del tipo de tarea y los datos utilizados.
MODELO CRÍTICO: Cuando el modelo de IA en entrenamiento está destinado a una tarea de gran importancia, en la que un margen de error, aunque sea pequeño, no es aceptable. Por ejemplo, en conducción autónoma, el vehículo conducido por un modelo de IA no se puede permitir errores, porque resultarían en accidente de tráfico. En estos modelos, el porcentaje de acierto debe ser cercano al 100%.
MODELO FUNDACIONAL: Es un tipo de modelo de gran escala que se entrena con enormes cantidades de datos no supervisados y que luego puede adaptarse a diversas tareas. Estos modelos son generalistas y pueden aplicarse a múltiples dominios, desde procesamiento de lenguaje natural hasta visión por computadora, sin necesidad de empezar de cero. Ejemplos de modelos fundacionales incluyen GPT y BERT. Son llamados "fundacionales" porque sirven como base para el desarrollo de aplicaciones más específicas mediante técnicas como el fine-tuning.
MULTIMODAL: En inteligencia artificial se refiere a la capacidad de un modelo o sistema para procesar y combinar diferentes tipos de datos o modalidades, como texto, imágenes, audio, video, o incluso señales sensoriales, para generar una respuesta o realizar una tarea. Los modelos multimodales integran información de varias fuentes para mejorar la comprensión y generar resultados más precisos. Un ejemplo es un sistema que puede interpretar una imagen (visión) y generar una descripción (texto) o un chatbot que puede comprender tanto el lenguaje hablado (audio) como el escrito (texto).
NEURONAS: En el contexto de inteligencia artificial, las neuronas son los componentes básicos de las redes neuronales artificiales. Imitan el comportamiento de las neuronas biológicas en el cerebro. Cada neurona recibe entradas (datos), las procesa aplicando una función matemática (función de activación) y luego pasa la información resultante a otras neuronas. A través de este proceso, las neuronas trabajan juntas en múltiples capas para aprender patrones complejos a partir de los datos y tomar decisiones o hacer predicciones.
NLP (Natural Language Processing): Oprocesamiento del lenguaje natural es un campo de la inteligencia artificial que se centra en la interacción entre las máquinas y el lenguaje humano. El objetivo de NLP es permitir que las computadoras comprendan, interpreten y generen lenguaje de manera similar a los humanos. Las aplicaciones de NLP incluyen chatbots, traducción automática, análisis de sentimientos, resumen de texto, reconocimiento de voz, y más.
NoSQL: Es un tipo de base de datos que no sigue el modelo relacional tradicional basado en tablas como las bases de datos SQL. En lugar de eso, utiliza diferentes modelos de datos como documentos, claves-valor, gráficos o columnas. Las bases de datos NoSQL son especialmente adecuadas para manejar grandes volúmenes de datos no estructurados o semiestructurados y ofrecen mayor flexibilidad y escalabilidad que las bases de datos relacionales. Son comúnmente usadas en aplicaciones que requieren alta disponibilidad y rendimiento, como big data, redes sociales y aplicaciones en tiempo real.
OCR (pattern recognition): O reconocimiento óptico de caracteres, es una tecnología que permite convertir imágenes de texto impreso o escrito a mano en texto digital editable. El OCR analiza las imágenes de documentos, fotos o escaneos para identificar y extraer los caracteres, permitiendo que el contenido se pueda editar, buscar o procesar por máquinas. Es ampliamente utilizado en la digitalización de documentos, procesamiento de facturas, y lectura automática de formularios o libros.
ONE SHOT PROMPTING: Es una técnica en la que se proporciona a un modelo de inteligencia artificial un solo ejemplo o instrucción para realizar una tarea específica. En lugar de entrenar el modelo con muchos ejemplos (como en el aprendizaje tradicional), se le muestra un solo caso para que comprenda la tarea. Esta técnica es útil en modelos avanzados de lenguaje natural, como los modelos grandes (LLMs), que pueden generalizar bien incluso con poca información, realizando correctamente la tarea basándose en ese único ejemplo.
OVERFITTING: O sobreajuste, es cuando un modelo de Machine Learning se ajusta demasiado a los datos de entrenamiento, aprendiendo tanto los patrones como el ruido específico de esos datos. Como resultado, el modelo tiene un rendimiento excelente en el conjunto de entrenamiento pero falla en generalizar a datos nuevos, mostrando baja precisión en el conjunto de prueba.
PERCEPTRÓN: Es el componente más básico de una red neuronal artificial y representa una sola neurona. Fue uno de los primeros modelos de machine learning, diseñado para clasificar datos binarios. Un perceptrón recibe varias entradas, las pondera con ciertos pesos, suma los resultados y aplica una función de activación para producir una salida (normalmente 0 o 1). Si la salida supera un umbral, se activa; si no, no. Aunque simple, es la base de redes neuronales más complejas utilizadas en el deep learning.
PIPELINE: Es una serie de pasos secuenciales y automatizados que procesan datos y entrenan modelos de manera eficiente. Cada paso en el pipeline realiza una tarea específica, como la recolección de datos, preprocesamiento, entrenamiento del modelo, validación y despliegue. Los pipelines ayudan a organizar y estructurar el flujo de trabajo, facilitando la repetición del proceso y la integración de diferentes componentes.
PLATEAU: En inteligencia artificial se refiere a un punto en el proceso de aprendizaje automático donde el rendimiento del modelo no mejora significativamente, a pesar de seguir entrenándolo con más datos o ajustando los parámetros. Es como si el modelo hubiera alcanzado un techo y no pudiera superarlo fácilmente. Esto suele ocurrir cuando el modelo ha aprendido todas las patrones relevantes en los datos disponibles y necesita más información o una reformulación del problema para avanzar.
PRE-PROMPT (Prompt de sistema): Se refiere a un texto o instrucción que se proporciona a un modelo de inteligencia artificial antes de presentar la tarea principal o la pregunta específica. Se utiliza para establecer el contexto, guiar la respuesta o influir en el tono y el estilo de la salida generada por el modelo. Los pre-prompts son útiles para mejorar la calidad y relevancia de las respuestas, ya que ayudan al modelo a entender mejor lo que se espera de él antes de recibir la consulta principal.
PROMPT (Prompt de chat): Es una instrucción o un conjunto de palabras que se le da a un modelo de inteligencia artificial para guiar su respuesta o generación de contenido. En el contexto de modelos de lenguaje, el prompt puede ser una pregunta, un tema o una frase inicial que el modelo utiliza para generar texto relacionado. La calidad y claridad del prompt son cruciales, ya que afectan directamente la relevancia y precisión de la respuesta que proporciona el modelo.
PROMPT-GRAMMING / PROMP ENGINEERING: Es un enfoque que implica diseñar y ajustar cuidadosamente los prompts para interactuar eficazmente con modelos de inteligencia artificial, especialmente modelos de lenguaje como los LLM (Large Language Models). Este término combina "prompt" (instrucción) y "programming" (programación) para enfatizar que la creación de prompts se puede considerar una forma de programación. Al igual que en la programación tradicional, donde se deben seguir ciertas reglas y estructuras, el prompt-gramming requiere entender cómo los modelos responden a diferentes formulaciones y contextos para obtener los resultados deseados. Es una habilidad importante para optimizar la interacción con modelos de IA y mejorar la calidad de las respuestas generadas.
PYTHON: Es un lenguaje de programación de alto nivel, interpretado y de propósito general, conocido por su sintaxis clara y legible. Es ampliamente utilizado en diversas áreas, incluyendo desarrollo web, análisis de datos, inteligencia artificial, machine learning, automatización de tareas, y más. Python cuenta con una rica colección de bibliotecas y frameworks, como NumPy, pandas, TensorFlow y Flask, que facilitan el desarrollo y la implementación de proyectos complejos. Su popularidad se debe a su facilidad de aprendizaje, versatilidad y fuerte comunidad de usuarios.
PYTORCH: Es una biblioteca de código abierto para el aprendizaje automático y la inteligencia artificial, especialmente conocida por su flexibilidad y facilidad de uso en la investigación de deep learning. Desarrollada por Facebook, PyTorch permite construir y entrenar modelos de redes neuronales mediante un enfoque dinámico que facilita la depuración y la experimentación. Su diseño basado en tensores permite realizar cálculos eficientes en CPU y GPU, y ofrece una amplia gama de herramientas y módulos que simplifican tareas como la manipulación de datos, la construcción de modelos y la optimización. Es muy popular en la comunidad de investigadores y desarrolladores por su capacidad de facilitar prototipos rápidos y su integración con otras bibliotecas.
REDES NEURONALES: Son modelos computacionales inspirados en el cerebro humano, compuestos por capas de neuronas artificiales que procesan datos. Se utilizan para reconocer patrones y resolver problemas complejos. Existen varios tipos, como las redes feedforward, las convolucionales (CNN) para imágenes y las recurrentes (RNN) para secuencias de datos. Se entrenan mediante algoritmos de aprendizaje automático para mejorar su precisión en tareas como clasificación y regresión.
RETRIEVAL: O recuperación, se refiere al proceso de buscar y obtener información relevante de un conjunto de datos o una base de datos. En el contexto de inteligencia artificial y machine learning, se utiliza comúnmente en sistemas de recuperación de información, como motores de búsqueda y sistemas de recomendación. El objetivo del retrieval es identificar y presentar los datos más pertinentes en respuesta a una consulta del usuario, basándose en técnicas como la indexación, el análisis semántico y algoritmos de ranking.
ROBUSTEZ: La robustez de un dataset se refiere a su capacidad para mantener la calidad y validez de los resultados, incluso ante variaciones, ruido o errores en los datos. Un dataset robusto proporciona resultados consistentes y precisos, lo que asegura que los modelos entrenados con él puedan generalizar bien a nuevos datos y no sean sensibles a anomalías.
RUIDO: En el contexto de datos y machine learning, el ruido se refiere a la información irrelevante, errónea o aleatoria presente en un conjunto de datos que puede interferir con el análisis o el rendimiento de un modelo. El ruido puede surgir de diversas fuentes, como errores de medición, variaciones aleatorias en los datos o datos no representativos. La presencia de ruido puede dificultar la identificación de patrones reales y afectar la precisión de las predicciones del modelo, por lo que es fundamental limpiar y preprocesar los datos antes de su uso.
SCIKIT-LEARN: Es una biblioteca de código abierto para Python que proporciona herramientas simples y eficientes para el aprendizaje automático y la minería de datos. Está diseñada para trabajar con datos estructurados y ofrece una amplia gama de algoritmos para tareas de clasificación, regresión, clustering y reducción de dimensionalidad. Scikit-learn incluye funcionalidades para la preprocesamiento de datos, validación de modelos y selección de características, lo que la convierte en una opción popular tanto para principiantes como para expertos en machine learning. Su diseño intuitivo y su integración con otras bibliotecas de Python, como NumPy y pandas, la hacen muy accesible para el análisis de datos
SCRAPPING: O web scraping, es el proceso de extraer información de sitios web de manera automatizada. Implica el uso de programas o scripts que recorren las páginas web, analizan el contenido HTML y recopilan datos específicos, como texto, imágenes, precios, o cualquier otra información relevante. El scraping se utiliza en diversas aplicaciones, como la recopilación de datos para análisis de mercado, la monitorización de precios, la investigación académica y la creación de bases de datos. Es importante tener en cuenta que el scraping debe realizarse respetando las políticas de uso de los sitios web y las leyes de protección de datos.
SDK: O Software Development Kit, es un conjunto de herramientas, bibliotecas y documentación que permite a los desarrolladores crear aplicaciones para una plataforma específica. Un SDK incluye todo lo necesario para desarrollar software, como APIs (Interfaces de Programación de Aplicaciones), ejemplos de código, herramientas de depuración y entornos de desarrollo. Los SDKs son comunes para sistemas operativos, plataformas de desarrollo de aplicaciones móviles, servicios en la nube y otras tecnologías, facilitando a los desarrolladores la integración de funcionalidades y la creación de aplicaciones más rápidamente.
SQL: O Structured Query Language, es un lenguaje de programación utilizado para gestionar y manipular bases de datos relacionales. Permite realizar operaciones como consultar, insertar, actualizar y eliminar datos en una base de datos. SQL utiliza una sintaxis estructurada que incluye comandos como SELECT, INSERT, UPDATE, DELETE, y CREATE TABLE, entre otros. Es fundamental para el manejo de datos en sistemas de gestión de bases de datos (DBMS) como MySQL, PostgreSQL, Oracle y Microsoft SQL Server, y es ampliamente utilizado en aplicaciones empresariales y análisis de datos.
TENSORFLOW: Es una biblioteca de código abierto desarrollada por Google para el aprendizaje automático y el deep learning. Proporciona un marco flexible y escalable para construir y entrenar modelos de inteligencia artificial. TensorFlow es especialmente útil para trabajar con redes neuronales y ofrece una variedad de herramientas y recursos, como Keras, que simplifican el desarrollo de modelos. Su capacidad para ejecutar cálculos en múltiples CPUs y GPUs lo hace adecuado para tareas complejas y grandes volúmenes de datos. TensorFlow es ampliamente utilizado en aplicaciones de visión por computadora, procesamiento del lenguaje natural y otras áreas de IA.
TOKEN: Especialmente en modelos de lenguaje como GPT, un token es una unidad de texto que el modelo utiliza para procesar y generar respuestas. Un token puede ser una palabra completa, parte de una palabra o incluso un solo carácter, dependiendo del modelo y el idioma. Los modelos dividen el texto en tokens para analizarlo y entenderlo. Por ejemplo, en inglés, la palabra "fantastic" podría dividirse en varios tokens, mientras que palabras más cortas como "dog" podrían ser un solo token. El número de tokens influye en el tamaño de la context window que el modelo puede manejar.
TRANSFORMER: Es un modelo de arquitectura de red neuronal utilizado principalmente en el procesamiento del lenguaje natural (NLP) y otras tareas de inteligencia artificial. Introducido en el artículo "Attention is All You Need" en 2017, el transformer se basa en el mecanismo de atención, que permite al modelo ponderar la importancia de diferentes palabras en una oración al realizar tareas como traducción, resumen y generación de texto.
Los transformers son eficaces para manejar secuencias de datos y pueden procesar múltiples palabras simultáneamente, lo que los hace más rápidos y escalables que modelos anteriores, como las redes neuronales recurrentes (RNN). Gracias a su capacidad para capturar dependencias a largo plazo en los datos, los transformers han revolucionado el campo del NLP y han dado lugar a modelos avanzados como BERT y GPT.
TTS (Text To Speech): Es una tecnología que utiliza IA para convertir texto escrito en habla sintetizada. Funciona mediante algoritmos que procesan el lenguaje natural y lo transforman en audio. Permite hacer accesible el texto a personas con discapacidades visuales o que prefieren consumir información auditivamente. Las voces generadas han mejorado significativamente en cuanto a naturalidad y expresividad emocional gracias a avances en aprendizaje automático y grandes bases de datos de habla humana. Los desarrolladores pueden integrar estas funcionalidades en aplicaciones mediante APIs, facilitando su implementación en diferentes plataformas y servicios.
VECTOR: Es una secuencia ordenada de números, normalmente en una sola dimensión, como una lista de valores. Es común en IA para representar datos o características de un objeto (por ejemplo, una imagen o una palabra) en una sola dirección. Los vectores son utilizados en álgebra lineal y se emplean para representar puntos en el espacio, entre otras cosas.
📊 LOS DATOS
Los datos son la gasolina del Machine Learning, sin datos no hay Machine Learning. Los datos se pueden clasificar, tratar y organizar de diferentes maneras, dependiendo de su valor y su complejidad. En resumen, la inteligencia artificial necesita de una ingente cantidad de datos para ser entrenada en una o varias tareas, y operar con una lógica y criterio aprendidos.
A mayor cantidad y calidad de los datos, mayor acierto de la IA en su cometido específico.
► TECONOLOGÍAS AL REDEDOR DEL DATO:

Artificial Intelligence / Inteligencia Artificial:
Tecnología capaz de automatizar tareas y/o resolver problemas. Puede simular la inteligencia humana, entender y generar datos de diferente naturaleza.
Machine Learning / Aprendizaje Automático:
El uso de algoritmos para analizar y clasificar datos, de forma que estos sirvan de aprendizaje a un modelo de IA.
Deep Learning / Aprendizaje Profundo:
Parte del Machine Learning que utiliza redes neuronales. Las redes neuronales se inspiran en la estructura y funcionamiento del cerebro humano, enseñando a las computadoras a procesar datos de una manera similar, realizando mediante algoritmos, un incontable número de iteraciones entre las diferentes combinaciones y posibilidades resultantes de los datos disponibles.
En resumen, el Deeplearning es una subdisciplina del Machine Learning que utiliza el algoritmo llamado redes neuronales para poder sacar conclusiones de datos no estructurados.
Data Science / Ciencia de Datos:
El estudio de los datos y la búsqueda de posibles aplicaciones de éstos. Llevado a cabo por Data Scientists, programadores capaces de trabajar estos datos, tanto "brutos" como "refinados", mediante código tradicional. Su trabajo pasa tanto por explicar situaciones empresariales como por hacer predicciones, ayudándose de herramientas de visualización.
Big Data / Datos Masivos:
Aquellos conjuntos de datos masivos y complejos que son difíciles de procesar con herramientas tradicionales. Pueden ser bases de datos SQL o NoSQL. A menudo recopilados de forma automática por dispositivos IoT.
Data Analytics / Análisis de Datos:
Acción de analizar, limpiar y clasificar datos para su uso posterior de forma más eficiente. Llevada acabo por Data Analysts. Ésta práctica se conoce comúnmente como ETL (Extract, Transform and Load) convirtiendo los datos "brutos" en "refinados", es decir, en información útil para el Machine Learning.
► ETAPAS DEL PROCESO DE ANÁLISIS DE DATOS
1 - Recopilación de datos: Reunir datos relevantes de diversas fuentes
2 - Limpieza de datos: Eliminar errores, duplicados y valores faltantes para mejorar la calidad
3 - Preparación de datos: Transformar los datos para que sean adecuados para el análisis
4 - Análisis de datos: Aplicar técnicas para encontrar patrones o relaciones
5 - Visualización de datos: Visualizar esos datos en métricas y gráficos que ayuden a su comprensión
6 - Interpretación de datos: Extraer conclusiones y dar sentido a los hallazgos para la toma de decisiones
► CICLO DE VIDA DE LOS DATOS

📚
🧹
⚙️
🔎
📊
💬
► ESTRUCTURA DE LOS DATOS
Los datos se pueden ordenar en bases de datos, en las que según su naturaleza, se dividen en dos tipos:
- Bases de datos ESTRUCTURADOS (SQL): Organizan datos en tablas con formato definido, como filas y columnas
- Bases de datos NO ESTRUCTURADOS (NoSQL): Contienen datos sin un formato fijo, como texto, imágenes o videos

CARACTERÍSTICAS
Organización: Estructura predefinida como tablas
Uniformidad: Sigue un formato standard
Accesibilidad: Fácil de acceder y manipular
Numéricos: Números enteros, decimales, etc
Categóricos: Valores que representan categorías
Fechas y horas: Fechas y horas
CARACTERÍSTICAS
Formato libre: No siguen formato predefinido
Heterogeneidad: Texto, audio, vídeo, imagen...
Complejidad: Difíciles de procesar y analizar
Dificultades: De almacenar, procesar y analizar
Oportunidades: Información más valiosa
► TIPOS DE ANÁLISIS DE DATOS
La forma de analizar los datos se puede dividir en tres tipos:
- Análisis Descriptivo: Examina los datos para obtener información sobre lo que ha ocurrido u ocurre en el entorno de los datos. Mediante métricas, gráficos y visualizaciones de cuadros de mando.
- Análisis Exploratorio o de Diagnóstico: Examen profundo o para entender por qué ha ocurrido algo. Se caracteriza por el descubrimiento de correlaciones y patrones dentro de los datos. Entre otras aplicaciones, para entender picos y bajadas de las gráficas y encontrar anomalías.
- Análisis Predictivo: Llevar los datos predictivos al siguiente nivel, utilizando los datos históricos para hacer previsiones precisas sobre los patrones de datos que pueden producirse en el futuro.
► BIG DATA
Big Data se refiere a conjuntos de datos extremadamente grandes y complejos que son difíciles de procesar con herramientas tradicionales. Un ejemplo de Big Data sería el conjunto de datos resultantes de redes sociales como Facebook, Twitter o Instagram. A menudo estas bases de datos masivas se crean mediante procesos de recolección automático, o bien mediante programas y bien mediante dispositivos IoT cuyos sensores recopilan información de diferente naturaleza, como por ejemplo, una estación meteorológica que almacena periódicamente información sobre la temperatura o presión atmosférica. La Big Data requiere de tecnologías y herramientas que permitan la visualización de los datos.
Desafíos. Las 3 "V" de la Big Data son:
1 - Volumen: La organización y almacenado de ingentes cantidades de datos requiere de mucho espacio
2 - Velocidad: Mover y procesar tales cantidades de datos requiere de altas capacidades técnicas
3 - Variedad: Hace referencia a los diversos tipos de datos que puede almacenar, especialmente aquellos no estructurados
Casos de uso del Big Data:
- Desarrollo de productos: Por ejemplo, empresas de "video on demand" para adecuar sus servicios a lo que ven sus clientes.
- Mantenimiento productivo: Por ejemplo, sistemas industriales capaces de predecir fallos mecánicos analizando parámetros
- Prevención del fraude: Por ejemplo, en la identificación de patrones que puedan ser indicativos de fraude
📚 DATASETS
Un Dataset (conjunto de datos) es una colección estructurada de datos que se utiliza para análisis, entrenamiento de modelos de machine learning o procesamiento de información. Los Dataset son fundamentales en la ciencia de datos y la inteligencia artificial, ya que sirven como base para aprender, validar y aplicar modelos analíticos.
Un Dataset puede estar conformado desde por un solo archivo como por cientos o miles, organizados o no en subcarpetas según las necesidades que se requieran para entrenar al modelo.
Algunos modelos de lenguaje como ChatGPT-4 de OpenAI, se basan en una arquitectura de red neuronal conocida como "transformer". Aunque OpenAI no ha publicado cifras exactas sobre la cantidad de datos o parámetros que tiene ChatGPT-4, se estima que tiene cientos de miles de millones de parámetros. Toda esta base de datos masiva (Big Data) podríamos decir que es su Dataset. En términos de datos, se entrenó con un vasto conjunto de textos que incluye libros, artículos, sitios web y otros documentos. El volumen de datos utilizado para el entrenamiento es considerablemente grande, lo que permite que el modelo comprenda y genere texto de manera coherente y contextualmente relevante. Si bien no hay un número específico, se puede decir que el modelo se entrenó con datos que abarcan miles de millones de palabras. Esto le permite manejar una amplia gama de temas y responder preguntas de manera efectiva.
► ESTRUCTURA DE UN DATASET
Filas y Columnas:
Un dataset típicamente se organiza en forma de tabla, donde cada fila representa una instancia o un registro (un ejemplo o un caso) y cada columna representa una característica o variable asociada con esos registros.
Por ejemplo, en un dataset sobre propiedades inmobiliarias, cada fila podría representar una casa y las columnas podrían incluir características como "precio", "tamaño", "ubicación" y "número de habitaciones".
Tipos de Datos:
Las columnas pueden contener diferentes tipos de datos, como números (enteros o decimales), texto (cadenas de caracteres), fechas, categorías (datos categóricos) o booleanos (verdadero/falso).
Etiquetas:
En el contexto del aprendizaje supervisado, algunos datasets incluyen etiquetas, que son las respuestas o clases asociadas a cada instancia. Por ejemplo, en un dataset de imágenes de animales, las etiquetas podrían ser "gato" o "perro".
► TIPOS DE DATASETS
Datasets Estructurados:
Datos organizados en un formato tabular (como una base de datos relacional). Son fáciles de analizar y procesar con herramientas tradicionales de análisis de datos.
Datasets Semiestructurados:
Datos que no están organizados en un formato tabular, pero que contienen etiquetas o marcas que facilitan su análisis, como XML o JSON.
Datasets No Estructurados:
Datos que no tienen un formato predefinido, como texto libre, imágenes, videos o audio. Estos datos requieren técnicas específicas para su análisis, como procesamiento de lenguaje natural (NLP) o visión por computadora.
► CREACIÓN Y OBTENCIÓN DE DATASETS
Recolección de Datos:
Los datasets pueden ser recolectados a través de diversas fuentes, como encuestas, sensores, bases de datos públicas, scraping de web, y APIs.
Limpieza de Datos:
Antes de utilizar un dataset, es crucial limpiarlo para eliminar errores, datos duplicados o inconsistencias. Esto incluye el manejo de valores faltantes, la normalización de formatos y la eliminación de outliers.
Preprocesamiento:
El preprocesamiento incluye transformar los datos en un formato adecuado para el análisis. Esto puede incluir la conversión de datos categóricos a numéricos, escalado de características y segmentación de datos.
Importancia de los Datasets
Entrenamiento de Modelos:
En machine learning, la calidad y cantidad de datos en un dataset son cruciales para entrenar modelos precisos y robustos. Un dataset bien diseñado puede mejorar significativamente el rendimiento del modelo.
Validación y Evaluación:
Los datasets también son utilizados para validar y evaluar modelos. Esto se hace dividiendo el dataset en conjuntos de entrenamiento y prueba, asegurando que el modelo generalice bien a datos no vistos.
Toma de Decisiones:
Los datasets son esenciales para la toma de decisiones basada en datos en organizaciones y empresas, ayudando a identificar tendencias, patrones y correlaciones que pueden influir en la estrategia y operación.
► DESAFIOS ASOCIADOS A LOS DATASETS
Calidad de los Datos:
La calidad de un dataset puede variar, y datos de baja calidad pueden llevar a resultados erróneos. Es fundamental realizar auditorías de calidad de datos.
Tamaño y Escalabilidad:
Los grandes volúmenes de datos (Big Data) pueden ser difíciles de manejar y procesar, requiriendo herramientas y técnicas especializadas para su análisis.
Privacidad y Ética:
La recolección y uso de datos deben cumplir con normativas de privacidad y éticas, protegiendo la información personal y asegurando el uso responsable de los datos
📑 EJEMPLO DE DATASET DE TEXTO
🌐 https://www.kaggle.com/datasets/spscientist/students-performance-in-exams?select=StudentsPerformance.csv
Archivos:
En este ejemplo se muestra un Dataset publicado en Kaggle que consta de un solo archivo con información acerca de las notas académicas de 1000 alumnos de secundaria de EEUU, con etiquetas como su género, el nivel académico de sus padres, el tipo de almuerzo que realizan durante el horario lectivo, y otros parámetros similares.
Tipo:
El único archivo del Dataset sepuede descargar desde el botón Download y es un archivo de texto de tipo CSV:
StudentsPerformance.csv
📄 Ver archivos CSV
Vista previa en Kaggle:

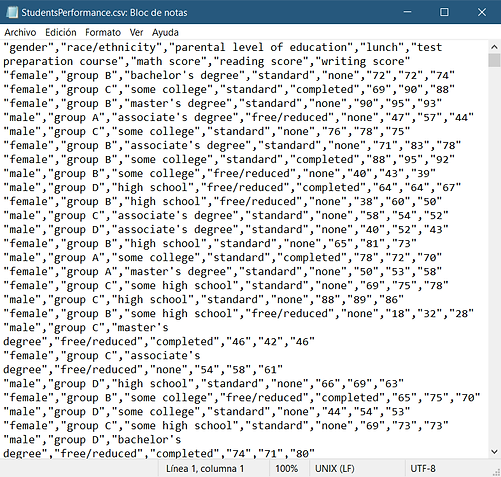
Vista del archivo descargado, con Bloc de Notas:
Como vemos, es un archivo de texto aparentemente sin formato ni sentido. En realidad, los datos están divididos mediante comas, que dibujan una tabla imaginaria que puede ser interpretada por otros programas.
Vista del archivo descargado, con Excel:
Extraídos los datos a una hoja de cálculo de Excel. Aquí sí se pueden visualizar los datos en tablas.

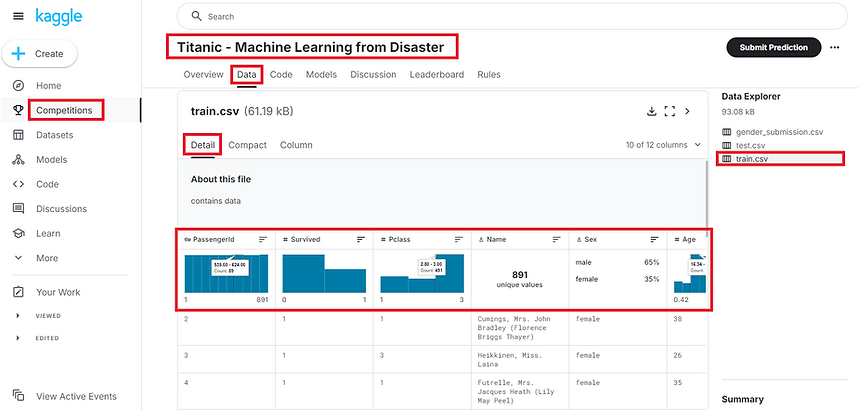
Vista completa del archivo en Kaggle:
La plataforma Kaggle ofrece un visualizador de archivos CSV que no solo muestra en tablas la información, si no que permite visualizar los datos divididos en porcentaje o con gráficas, según el tipo de valor. Por ejemplo en el caso del género, como solo hay dos valores, "male" y "female", automáticamente los muestra en porcentaje.

Resumen del Dataset:
El archivo contiene una serie de datos estructurados con los que el modelo puede ser entrenado para su análisis, y descubrir, por ejemplo, que factores de los disponibles influyen o pueden influir en las notas de los estudiantes. El modelo sería capaz de realizar cálculos matemáticos mediante algoritmos, que puedan por ejemplo, en base a los datos obtenidos, hacer una predicción de qué alumn@s sacarán mejores o peores notas el próximo curso.
🖼️ EJEMPLO DE DATASET DE IMÁGENES
🌐 https://www.kaggle.com/datasets/samuelcortinhas/cats-and-dogs-image-classification
Archivos:
Este Dataset está compuesto por dos carpetas principales, "train" y "test". Cada una de ellas tiene dos carpetas, "cats" y "dogs", con fotografísa etiquetadas de gatos y perros respectivamente (697 fotos en total). La carpeta "train" (entrenar) tiene más contenido que la carpeta "test" (prueba), esto es porque, el contenido de la carpeta "train" servirá para entrenar al modelo, y el contenido de la carpeta "test" para poner a prueba el modelo entrenado. Las fotos de "train" y "test" en sus respectivas carpetas "cats" y "dogs" son diferentes.
Vista previa en Kaggle:
En la imagen vemos que dentro de "test", en la carpeta "cats" hay 70 fotografías de gatos que se pueden visualizar online.

Vista del contenido descargado:
Un simple vistazo del contenido del archivo zip.

Resumen del Dataset:
Un Dataset como este serviría para entrenar a un modelo y que este sea capaz, posteriormente, de identificar y diferenciar gatos de perros en fotografías. A mayor número de fotografías y mayor calidad de imagen de éstas, más eficiente será el modelo entrenado en la tarea específica de diferenciar gatos de perros en imágenes.
🧰 RECURSOS PARA COMPUTACIÓN
¿CUÁL ES EL MOTOR DE LA IA?
El Machine Learning es una tecnología que detecta automáticamente patrones y relaciones entre datos para poder crear modelos de predicción o clasificación. El tipo de aprendizaje más popular es el llamado "aprendizaje supervisado". Para este, se necesita del empleo de muchos recursos humanos para poder etiquetar grandes cantidades de datos.
CLOUD COMPUTING
Si tenemos los recursos podemos desarrollar desde nuestro entorno local (máquina). Si no, tenemos que rentar los recursos de terceros.

PRINCIPALES PROVEEDORES DE CLOUD COMPUTING
🅰️ Amazon Web Services (AWS)
Pionero y líder del mercado con la mayor cuota. amplia experiencia y madurez en servicios cloud.
☁️ Google Cloud
Más joven, pero con un crecimiento rápido. Fortalezas en análisis de datos, aprendizaje automático e innovación.
🔵 Microsoft Azure
Fuertemente integrado con el ecosistema Microsoft. Atractivo para empresas que ya utilizan productos Microsoft.
HARDWARE
El DeepLearning necesita de GPUs (Graphic Processing Unit) o tarjetas gráficas. Se trata de una pieza de hardware que facilita paralelizar operaciones. Es ideal para operaciones con matrices. Igualmente, las máquinas que se utilicen con este propósito requieren de una alta velocidad de acceso a los datos, sobre todo cuando son masivos.
Para hacernos una idea, estas son las especificaciones técnicas de algunas "máquinas virtuales" disponibles en
"Google Colab" para hacer Machine Learning ejecutando Python:
T4 GPU (gratuita de uso limitado):
RAM del sistema: 12,7 GB
RAM de la GPU: 15 GB
Disco: 112,6 GB
L4 GPU (de pago por suscripción):
RAM del sistema: 53 GB
RAM de la GPU: 22,5 GB
Disco: 112,6 GB
BALANCE DEL CLOUD COMPUTING

📄 FORMATO CSV. Contiene Datos Estructurados para Bases de Datos SQL
Los archivos en formato CSV se utilizan para crear bases de datos estructuradas. Se caracterizan por crear tablas de datos mediante líneas de texto, separando los datos con comas. Estos archivos se pueden abrir con editores de texto simple como "Bloc de Notas" (Windows) o "Mousepad" (Linux) o con Microsoft Excel.
EJEMPLO DE TABLA EN CSV (la primera línea hace de "leyenda"):
Matrícula, Marca, Color, Entrada, Salida
0000ABC, BMW, azul, 10:00, 12:00
0000XXX, Suzuki, negro, 10:30, 11:00
0000WWW, Seat, Rojo, 09:00, 10:20
0000AAA, Kia, Rojo, 10:00, 10:30
VISUALIZAR ARCHIVOS CSV COMO TABLAS DE EXCEL:






VISUALIZAR ARCHIVOS CSV SUBIDOS A KAGGLE:
📄 FORMATO MD. Contiene Datos NO Estructurados para Bases de Datos NoSQL
Markdown es un lenguaje de marcado ligero que permite agregar formato y estructura a un texto. Está probado que la IA de OpenAI entiende mejor los prompts y responde mejor a estos cuando le son presentados en este lenguaje o en archivos con este formato (.md). Estos archivos se pueden abrir con editores de texto simple como "Bloc de Notas" (Windows) o "Mousepad" (Linux).
Entre otras ventajas, los textos en Markdown pueden ser convertido a otros formatos como HTML o PDF y es muy utilizado en plataformas como GitHub para documentar proyectos de programación.
FORMATO BÁSICO:
**negrita**
*cursiva*
***negrita y cursiva***
ESTRUCTURA JERÁRQUICA:
# Título principal
## Subtítulo
### Subsubtítulo
LISTAS SIN NUMERAR:
- elemento de una lista
- elemento de una lista
LISTAS ENUMERADAS:
1. elemento de una lista
2. elemento de una lista
CITAS:
> Texto con la cita
FORMATO DE TABLAS:
| Column 1 | Column 2 |
| ---------------- | ---------------- |
| Cell 1, Row 1 | Cell 2, Row 1 |
| Cell 1, Row 2 | Cell 1, Row 2 |
FORMATO DE FECHA:
Enero 15, 2024
URL con enlace interactivo:
[Referencia](https://www.example.com)
⚙️ MACHINE LEARNING
El término "Machine Learning" (ML) o aprendizaje automático, apareció por primera vez en 1952 para un programa de jugar ajedrez. Se llama así a la rama de la inteligencia artificial que permite a los sistemas aprender y mejorar automáticamente a partir de la experiencia sin ser explícitamente programados. Específicamente, se basa en el análisis de datos y en la identificación de patrones para hacer predicciones o decisiones.
El símil para entender el ML se puede hacer con un bebé que aprende a hablar, al que no se le da un manual de gramática, sino que se le expone a una interactuación directa con personas que usan el lenguaje, y él aprende por sí mismo.
El Machine Learning funciona de forma similar, se le proporciona a la computadora un conjunto de datos y ella aprende a reconocer patrones y realizar predicciones. A diferencia de los sistemas tradicionales, en ML, los algoritmos pueden aprender y mejorar a partir de datos.

⇦ Iteración:
Se refiere a un solo paso en el entrenamiento, en el cual el modelo procesa un lote de datos (también llamado batch). Cada iteración implica ajustar los parámetros del modelo en función del error calculado para ese lote.
No confundir con Epoch:
Es un ciclo completo en el que el modelo pasa por todos los datos de entrenamiento una vez. Un epoch incluye muchas iteraciones, tantas como sea necesario para procesar todos los datos de entrenamiento en lotes. Se verá más adelante.

⇦ Parámetros de un Modelo:
Los parámetros no son "pesos" en el sentido
tradicional, sino más bien las reglas y umbrales
que determinan las decisiones.
En cada iteración el algoritmo ajusta sus
parámetros para resolver mejor el problema.
MINIMIZAR EL ERROR:
En Machine Learning, buscamos minimizar el error, no eliminarlo completamente. El proceso de optimización ajusta los parámetros del modelo para reducir el error. Con el tiempo, las mejoras en la precisión del modelo se vuelven cada vez más pequeñas.
Entrenar el modelo por más tiempo consume recursos sin proporcionar mejoras significativas adicionales.
En Machine Learning, el objetivo es minimizar el error del modelo, pero siempre habrá un margen de error debido a la naturaleza compleja de los datos.
🧠 REDES NEURONALES
¿QUÉ SON LAS REDES NEURONALES?
Son redes compuestas de "neuronas artificiales", que son unidades básicas, generalmente organizadas en capas, que actúan como pequeñas unidades de computación.
Comparación simplificada entre neuronas BIOLÓGICAS y neuronas ARTIFICIALES:

Las neuronas artificiales y su función
Las neuronas artificiales son componentes informáticos diseñados para simular cómo funcionan las neuronas biológicas del cerebro humano. A partir de estas neuronas artificiales, es posible construir redes neuronales artificiales enfocadas a optimizar los sistemas de inteligencia artificial.
Estas neuronas funcionan de forma similar a las biológicas, ya que reaccionan a señales simuladas de manera similar a cómo una neurona real responde a señales eléctricas del sistema nervioso.
Cómo funciona una neurona artificial
Una neurona artificial recibe una o varias entradas (que simulan los estímulos que recibe una neurona real) y las combina para generar una salida o activación. Las entradas suelen tener diferentes "pesos", que influyen en cómo la neurona reacciona, y se procesan a través de una función de activación, que define si la neurona responderá y en qué medida. Estas funciones suelen ser no lineales, lo que significa que la respuesta no es proporcional a la entrada, simulando así la complejidad de las neuronas reales.

💬 LENGUAJE NATURAL (NLP - Natural Languaje Processing)
LENGUAJE NATURAL:
NLP (Natural Language Processing) es una rama de la inteligencia artificial que se enfoca en la interacción entre computadoras y el lenguaje humano. Su objetivo es permitir que las máquinas comprendan, interpreten, generen y respondan al lenguaje de manera natural, como lo hacen los humanos. Esto incluye tareas como análisis de texto, traducción automática, reconocimiento de voz, generación de texto, chatbots, y más.
El NLP combina técnicas de lingüística, informática y aprendizaje automático para procesar y analizar grandes cantidades de datos de texto o voz, habilitando aplicaciones como asistentes virtuales (Siri o Alexa), traducción en tiempo real (Google Translate), análisis de sentimientos en redes sociales, o resúmenes automáticos de documentos. Utiliza modelos como transformers (por ejemplo, BERT o GPT) y librerías como Hugging Face, NLTK o spaCy en Python para tareas como tokenización, reconocimiento de entidades, o generación de texto, transformando el lenguaje humano en datos que las máquinas pueden manipular y entender.
LLM - Large Languaje Model:
Un LLM es un tipo de modelo de inteligencia artificial basado en redes neuronales, especialmente "transformers", entrenado en enormes cantidades de datos de texto para comprender, generar y responder al lenguaje humano de manera natural. Estos modelos, como Phind, ChatGPT, Claude o Grok, son capaces de realizar tareas de procesamiento de lenguaje natural (NLP) como traducción, generación de texto, respuesta a preguntas, y razonamiento, gracias a su capacidad para captar patrones lingüísticos complejos.
EJEMPLO DE INTERFAZ DE UN LLM: https://grok.com/

¿QUÉ ES UN PROMPT?
Un prompt es una instrucción, pregunta o texto inicial proporcionado a un modelo de inteligencia artificial, como un modelo de lenguaje de gran escala (LLM), para guiar su comportamiento y obtener una respuesta específica. En esencia, es la forma en que los usuarios "hablan" con la IA, definiendo la tarea, el tono, el formato o el contexto de la respuesta, como pedirle que resuelva un problema, escriba un poema o explique un concepto. La calidad y claridad del prompt son cruciales, ya que determinan la precisión y utilidad de la salida del modelo; por ejemplo, un prompt vago puede generar respuestas imprecisas, mientras que uno detallado, como en la técnica de Cadena de Pensamiento (CoT), puede mejorar el razonamiento del modelo.
TIPOS DE PROMPTING:
1. Generación SIN CONTEXTO previo (Zero-Shot)
El modelo recibe una instrucción directa sin ejemplos ni contexto adicional, confiando únicamente en su entrenamiento previo para responder. Ejemplo: "Escribe un poema sobre la luna." Es simple, pero puede ser menos preciso si la tarea es compleja.
2. Generación con EJEMPLO previo (One-Shot)
Se proporciona un único ejemplo de la tarea junto con la instrucción, ayudando al modelo a entender el formato o estilo esperado. Ejemplo: "Aquí está un ejemplo de resumen: [ejemplo]. Ahora resume este texto: [texto nuevo]." Mejora la precisión al dar un punto de referencia.
3. Generación con VARIOS ejemplos previos (Few-Shot)
Se incluyen múltiples ejemplos (generalmente 2-5) para mostrar al modelo el patrón o estilo deseado. Ejemplo: "Aquí hay tres ejemplos de titulares: [ejemplo1, ejemplo2, ejemplo3]. Escribe un titular similar." Es más efectivo que one-shot para tareas específicas, ya que refuerza el contexto.
4. Cadena de pensamiento SIN CONTEXTO previo (Zero-Shot CoT)
Se pide al modelo que razone paso a paso sin ejemplos previos, solo con la instrucción de "piensa paso a paso". Ejemplo: "Resuelve este problema matemático y explica cada paso." Mejora el razonamiento en tareas lógicas, pero depende de la capacidad del modelo.
5. Cadena de pensamiento (COT, Chain of Thought)
El modelo es guiado a desglosar el problema en pasos explícitos, a menudo con ejemplos previos (few-shot CoT) o sin ellos (zero-shot CoT). Ejemplo: "Resuelve este acertijo: [problema]. Muestra los pasos: [ejemplo resuelto]. Ahora resuelve este." Es ideal para tareas complejas como matemáticas o programación, ya que estructura el razonamiento y reduce errores.
EL BUEN PROMPT:
Hablamos de "Buen Prompt" cuando estructuramos y sintetizamos el prompt (instrucciones para el modelo de IA) de manera que sea eficaz para obtener el resultado deseado, que la respuesta sea precisa, ordenada, concreta y sin "ruido" (información irrelevante).
Estructura del Buen Prompt:
Actúa como si fueras [rol]
[verbo] [qué] [para_qué]
Asegúrate de aplicar lo siguiente:
[Temas_a_tratar]
[Formato]
[Estilo]
[Tono]
[Audiencia]
[Otras_consideraciones]
Ten en cuenta el siguiente contexto:
[rol]
Hazme las preguntas que consideres para que puedas darme la mejor respuesta posible.
Hablamos
♓ PROBANDO KAGGLE
🌐 https://www.kaggle.com
Kaggle es una plataforma online que sirve como comunidad global para científicos de datos y profesionales del aprendizaje automático (Machine Learning). Kaggle permite a los usuarios encontrar y publicar conjuntos de datos, explorar y crear modelos en un entorno de ciencia de datos basado en la web. También ofrece herramientas y recursos para progresar en la ciencia de datos, incluyendo acceso gratuito a GPUs en forma de máquina virtual de navegador, y una gran cantidad de datos y códigos publicados por la comunidad.
Adicionalmente Kaggle también ofrece recursos de aprendizaje automático, un banco de trabajo basado en la nube para ciencia de datos y Machine Learning, concursos de aprendizaje con premios en efectivo, permite compartir datasets, código, y abre una plataforma pública de educación en IA con ejercicios prácticos y en fragmentos más manejables.
Para participar en Kaggle, tan solo es necesaria una cuenta de correo Google.
Actualmente Kaggle solo está disponible en ingles.
Desde el menú de usuario podemos acceder a crear un recurso nuevo, acceder a las competiciones abiertas, y a otros recursos acompartidos por la Comunidad, como Datasets, Modelos y Código. Si ya hemos iniciado algún proyecto podemos acceder a ellos desde "Your Work"
¿Qué es un Notebook?
Un Notebook en inteligencia artificial es un entorno interactivo donde puedes escribir y ejecutar código de manera secuencial, mezclando explicaciones en texto, gráficos y código Python. Los más comunes son los Jupyter Notebooks, muy usados para desarrollar, probar y documentar proyectos de IA, machine learning y análisis de datos.
¿Qué es un Dataset?
Un dataset en inteligencia artificial es un conjunto de datos estructurados que se utiliza para entrenar, validar y probar modelos de IA. Contiene información organizada en filas y columnas, donde las filas suelen representar ejemplos o instancias, y las columnas representan atributos o características. Los modelos de IA aprenden patrones a partir de estos datos para hacer predicciones o clasificaciones. Los archivos de datos estructurados normalmente se encuentran en formato CSV.
¿Qué es un Modelo?
En inteligencia artificial, un modelo es un algoritmo entrenado que aprende patrones a partir de un Dataset. Este modelo procesa datos nuevos para hacer predicciones, clasificaciones o tomar decisiones basadas en lo que ha aprendido durante el entrenamiento. Es la representación matemática del problema que se busca resolver.
Muchos modelos de IA funcionan en Python, uno de los lenguajes más populares para desarrollar inteligencia artificial y Machine Learning debido a sus bibliotecas especializadas. Además, su simplicidad y gran Comunidad lo hacen ideal para trabajar con IA.
Principales Bibliotecas de Python para entrenar Modelos de IA:
Pandas: Para manipulación y análisis de datos.
NumPy: Para cálculos matemáticos y operaciones con matrices.
Matplotlib: Para visualización de datos a través de gráficos.
Seaborn: Extensión de Matplotlib para hacer visualizaciones más atractivas.
Scikit-learn: Para algoritmos de machine learning y preprocesamiento de datos.
TensorFlow: Para construir y entrenar redes neuronales y modelos de deep learning.
PyTorch: Similar a TensorFlow, es popular para deep learning y redes neuronales.
Keras: Interfaz de alto nivel para crear redes neuronales, funciona sobre TensorFlow.
SciPy: Para cálculos científicos y matemáticos avanzados.
NLTK: Para procesamiento de lenguaje natural (NLP).
📋 ESTRUCTURA DE UN NOTEBOOK EN KAGGLE:

🚢 TITANIC TUTORIAL - Machine Learning from Disaster
🌐 https://www.kaggle.com/competitions/titanic/overview (challenge)
🌐 https://www.kaggle.com/code/alexisbcook/titanic-tutorial (tutorial de Alexis Cook)
Ejemplo práctico con la ejecución del "Tutorial Titanic" de Alexis Cook.
Esta es la legendaria competencia de Machine Learning (ML) del Titanic - el mejor primer desafío para sumergirnos en las competencias de ML y familiarizarnos con cómo funciona la plataforma de Kaggle.
La misión es sencilla:
Utilizar el Machine Learning para crear un modelo que prediga, utilizando datos de una lista de pasajeros en la que se sabe quienes sobrevivieron y quienes fallecieron, qué pasajeros sobrevivieron al hundimiento del barco Titanic de otra lista en la que este dato es desconocido.
¿Qué datos usaré en esta competencia?
En esta competencia, tendrás acceso a dos conjuntos de datos similares que incluyen información de los pasajeros como nombre, edad, género, clase socioeconómica, etc.
Un conjunto de datos se llama train.csv y el otro se llama test.csv.
Train.csv contendrá los detalles de un subconjunto de los pasajeros a bordo (exactamente 891) y, lo más importante, revelará si sobrevivieron o no, lo que se conoce como la "verdad objetiva". Si abrimos el archivo, este dato se representa en la correspondiente columna con un "1" si el pasajero sobrevivió, o con un "0" si falleció en el accidente.
El conjunto de datos test.csv contiene información similar pero no revela la "verdad objetiva" de cada pasajero.
El OBJETIVO es predecir estos resultados. Usando los patrones que encuentres en los datos de train.csv, debes predecir si los otros 418 pasajeros a bordo (encontrados en test.csv) sobrevivieron.
Consulta la pestaña "Data" para explorar más a fondo los conjuntos de datos:

En un breve vistazo se pueden hacer varias observaciones generales de los datos contenidos en el archivo train.csv, que es el que contiene la información con la que entrenar al modelo, es decir, los datos que tendrá en cuenta para calcular y hacer predicciones.
Por ejemplo, observamos que en efecto hay un total de 891 pasajeros en la columna "PassengerId", que sobrevivieron un total de 342 (falleciendo 549), o que del total de esta tripulación, el 65% eran hombres y el 35% mujeres.
Para empezar a trabajar, es necesario abrir un nuevo "Notebook" desde la pestaña "Code". Los Notebooks son las áreas de trabajo estructurados en cascada. Pueden parecer un documento de texto, con la particularidad de que la máquina virtual que se ejecuta desde la plataforma puede correr código en Python, e ir mostrando los outputs resultantes en orden de aparición.

A continuación, visualización del Notebook según lo abrimos.
Primero hay que ejecutar la máquina virtual con el botón de "on". Si lo deseamos, podemos darle nombre al Notebook en la esquina superior izquierda. Debajo, viene predefinido un input en formato de texto que se ejecutará al tocar el Botón Play. Esto devolverá un output debajo, mostrando el Dataset de archivos subidos.

En adelante, vamos desgranando el código en Python y los outputs resultantes en cascada, como lo mostraría el Notebook, tomando como referencia el tutorial de Alexis Cook. Abajo se muestran los comentarios traducidos y explicaciones adicionales.
🔽[INPUT 1] -----------------------------------------------------------------------------------------------------------------------------------------
# Este entorno de Python 3 viene con varias librerías analíticas preinstaladas
# Definido por la imagen Docker: https://github.com/kaggle/docker-python
# Paquetes útiles para cargar
import numpy as np # liálgebra lineal
import pandas as pd # Procesamiento de datos, CSV file I/O (e.g. pd.read_csv)
# NUMPY (alias definido: np) es una biblioteca que proporciona numerosas funciones matemáticas. Realiza operaciones matemáticas avanzadas sobre grandes cantidades de datos numéricos.
# PANDAS (alias definido: pd) es una biblioteca clave para la manipulación y análisis de datos. Ofrece estructuras como "dataframes" y "series". Pandas permite CARGAR, EXPLORAR y MANIPULAR fácilmente archivos CSV.
# Archivos de datos del input están solo disponibles en la ruta "../input/" directory
# Por ejemplo, ejecutando esto (botón Play o pulsando Shift+Enter) se listarán todos los archivos en el output
# El siguiente código recorre el directorio (/kaggle/input/) + todos sus subdirectorio, buscando y listando los archivos existentes con sus rutas completas.
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# Además, se pueden subir hasta 20gb de data al directorio (/kaggle/working/) que "coge output reservado" cuando se crea una versión usando "save & run all"
# También se pueden escribir archivos temporales en (/kaggle/temp/) pero estos no se guardarán más allá de la presente sesión
[OUTPUT]
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csv
[NOTA]
Los archivos TRAIN.CSV (training data):
Contienen los datos que el modelo va a usar para "aprender". Se utilizan para ajustar los parámetros del modelo. Aquí el modelo examina los ejemplos y "aprende" patrones o relaciones entre las variables (inputs) y las etiquetas o resultados (outputs).
Los archivos TEST.CSV (testing data):
Deben contener un conjunto de datos NUEVOS, que el modelo no ha visto antes (en el train.csv). Se utiliza para evaluar el rendimiento del modelo después de haber sido entrenado. Estos archivos no modifican el modelo, solo lo ponen a prueba.
🔽[INPUT 2] -----------------------------------------------------------------------------------------------------------------------------------------
# El código a continuación leerá el archivo dado (train.csv) mediante la librería "Pandas", en un "dataframe" o estructura de datos bidimensional que se asemeja a una tabla.
# EL método .head() ofrece una vista rápida del principio del archivo (5 primeras líneas)
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
[OUTPUT]

🔽[INPUT 3] -----------------------------------------------------------------------------------------------------------------------------------------
# El código a continuación hace lo mismo que el anterior, pero con el archivo text.csv, donde veremos que falta la columna "Survived", es decir, que de la segunda lista de pasajeros desconocemos si sobrevivieron o no, que es lo que el Modelo tiene que ser capaz de predecir mediante cálculos probabilísticos en base a os datos que tenemos de la primera lista de pasajeros del archivo train.csv
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
[OUTPUT]
